SQL Server Kvantitetsprestandaanalys #2
Förord
 Här beskrivs de verktyg och testscript som behövs för att kunna utforska exekveringsplanens kostnadsformler. Det krävs också att man har en relativt stor förståelse av tabeller och Index för att kunna hänga med i våra teorier gällande SQL-sats kostnader och prestanda. Vissa av ämnena här finns beskrivna mer detaljerat i någon annan artikel, så diskussionerna här kommer inte att vara långa. SQL Server verktygen inkluderar Query Analyzer och Profiler. SET inställningen inkluderar SET STATISTICS IO och SET SHOWPLAN_ALL. Testtabellerna har skapats specifikt för att utforska en SQL-sats exekveringsplans kostnadsstruktur. Ni kan även se de script som används för att fylla en testtabell med specifika datadistributioner.
Här beskrivs de verktyg och testscript som behövs för att kunna utforska exekveringsplanens kostnadsformler. Det krävs också att man har en relativt stor förståelse av tabeller och Index för att kunna hänga med i våra teorier gällande SQL-sats kostnader och prestanda. Vissa av ämnena här finns beskrivna mer detaljerat i någon annan artikel, så diskussionerna här kommer inte att vara långa. SQL Server verktygen inkluderar Query Analyzer och Profiler. SET inställningen inkluderar SET STATISTICS IO och SET SHOWPLAN_ALL. Testtabellerna har skapats specifikt för att utforska en SQL-sats exekveringsplans kostnadsstruktur. Ni kan även se de script som används för att fylla en testtabell med specifika datadistributioner.
Introduktion
av Joe Chang
Tabellorganisation och Indexstruktur
I SQL Server lagras tabeller och Index som en samling 8kb datasidor. Det finns en mer detaljerad beskrivning av tabell- och Indexarkitektur på SQL Server Books Online. Tabellorganisation och Indexstruktur har både en viktig innebörd för prestanda, och de kommer att diskuteras lite kort här. En tabell organiseras som antingen en grupp (heap) eller som ett Clustrat Index. En tabell kan antingen ha ett eller inget Clustrat Index (vyindex diskuteras senare). En tabell utan ett Clustrat Index är en grupp. Poster i en grupp lagras inte i någon sorterad ordning. Figur 1 visar ett diagram av en grupporganiserad tabell.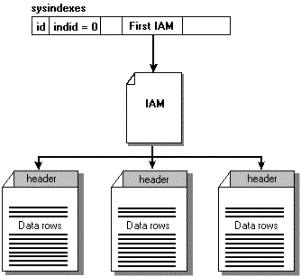
Figur 1: En grupporganiserad tabell
I tabeller med ett Clustrat Index så lagras poster i en sorterad ordning baserat på nyckelvärdet. Roten och alla mellanliggande nivåer av ett Clustrat Index innehåller Indexvärden. Lövnivån innehåller hela dataposten förutom datatyperna TEXT och IMAGE (under vissa omständigheter). Figur 2 visar en organisation av en tabell med ett Clustrat Index.
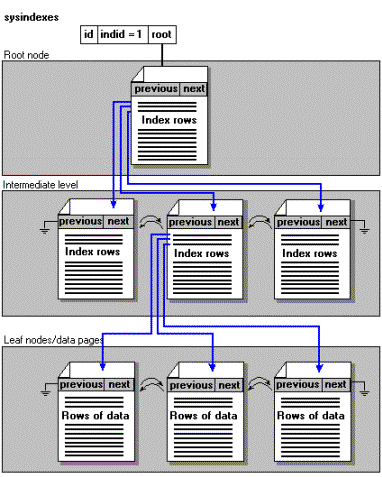
Figur 2: Tabellstrukturen av ett Clustrat Index
Den information som erhålls i ett icke-Clustrat Index beror på huruvida den underliggande tabellen är en grupp eller ett Clustrat Index. Vid en grupporganiserad tabell så innehåller det icke-Clustrade Indexet en fullständig pointer till posten, vilken inkluderar filer, sidor och lokalisering av posten. Figur 3 visar ett icke-Clustrat Index på en grupp. Notera att rot- och lövnoderna tillhör det icke-Clustrade Indexet. Mellanliggande Index visas inte i det här Indexet. Alla data tillhör den grupporganiserade tabellen.
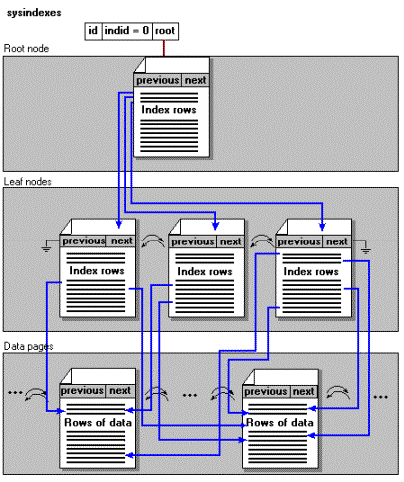
Figur 3: Ett icke-Clustrat Index byggt på den grupporganiserade tabellen
Vid en tabell med ett Clustrat Index så innehåller det icke-Clustrade Indexet nyckeln till det Clustrade Indexet. Prestandaproblemet med det är att Bookmark Lookup operationen följs av en icke-Clustrad Indexsökning, beroende på tabellens organisering. Vid en grupporganiserad tabell så är Bookmark Lookup verkligen en Lookup operation. Vid ett Clustrat Index så är Bookmark Lookup en extra Index Seek operation mot det Clustrade Indexet.
SQL Serverns tjänster och verktyg
Exekveringsplanens kostnadsinformation kan erhållas på flera olika sätt. Exekveringsplanen kan visas grafiskt i SQL Query Analyzer med någon av funktionerna ”Display Estimated Execution Plan” eller ”Show Execution Plan”. Kostnaden för varje komponentoperation visas som en procentuell del av den totala kostnaden för SQL-satsen, vilket visas i Figur 4 nedan. Om det finns fler än en SQL-sats så visas också kostnaden för varje SQL-sats som en procentuell del av den totala kostnaden av alla SQL-satser. 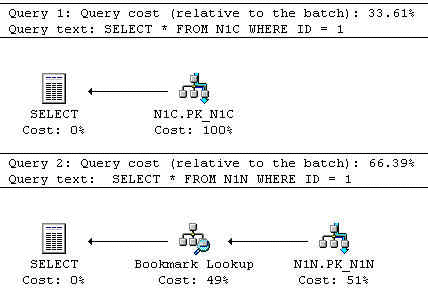
Figur 4: Outputen av ”Display Estimated Execution Plan” vid två SQL-satser
Den numeriska kostnaden av varje komponentoperation visas i det detaljfönstret som visas då du placerar muspekaren över en specifik komponent. Kostnaden av varje komponentoperation beror på hur många poster eller sidor som är involverade. Funktionen ”Display Estimated Execution Plan” genererar en exekveringsplan utan att egentligen exekvera SQL-satsen. Antalet poster eller sidor som är involverade i varje operation kan avgöras om du specificerar primärnyckeln eller något annat unikt Index. Det kan också avgöras från den statistiska information (som genereras och erhålls automatiskt av SQL Server) på de tabeller i de kolumner som använder ett sökargument (SARG). Funktionen ”Show Execution Plan” exekverar SQL-satsen så att man får reda på det exakta antalet poster och sidor som är involverade i varje operation. Kostnadsvärdet representerar den exakta formelkostnaden för en SQL-sats, baserat på det faktiska antalet poster och sidor som är involverade.
Figur 5 visar de kostnadsdetaljer som erhålls genom att välja funktionen ”Display Estimated Execution Plan”. Den uppskattade posträkningen är exakt 1, eftersom sökargumentet råkar vara en primärnyckel.

Figur 5: Kostnadsdetaljer för Index Seek från ”Display Estimated Execution Plan”
Figur 6 visar de kostnadsdetaljer som erhålls genom att välja funktionen ”Show Execution Plan”. Här är inte antalet poster, exekveringar och kostnader längre beräknade.

Figur 6: Kostnadsdetaljer för Index Seek från ” Show Execution Plan”
Exekveringsplanens detaljer kan också erhållas från någon av följande SET inställningar: SHOWPLAN_ALL, SHOWPLAN_TEXT, SET STATISTICS PROFILE, och andra källor som inkluderar Profilern. Kostnadsinformationen från SET SHOWPLAN_ALL är mer preciserad och har ett mer preciserat innehåll än de värden som visas grafiskt, vilka kan avrundas till ett fåtal viktiga siffror. Figur 7 visar ett exempel på Output från SET SHOWPLAN_ALL.

Figur 7: Outputen från SHOWPLAN_ALL
Varje komponentoperation har en I/O kostnad och en CPU kostnad. Den totala kostnaden av komponentoperationen är summan av I/O och CPU kostnaden, endast då antalet exekveringar är 1. Om antalet exekveringar är fler än en så blir kostnaden helt enkelt summan av I/O och CPU kostnaden multiplicerat med antalet exekveringar. Kostnaden av subträdet inkluderar kostnaden av alla operationer som matas in i den här specifika komponentoperationen.
Avdelningen där man mäter kostnaden för SQL Serverns exekveringsplan är inte dokumenterad. Man vet att kostnadsvärdena är desamma för både SQL Server 7.0 och SQL Server 2000 på en given plattform, inkluderat Standard- och Enterpriseutgåvorna och alla Servicepacks. I/O kostnaden för Index Seek- och Bookmark Lookup-operationerna beror på huruvida systemet har upp till 1 GB minne, eller mer än 1 GB minne. CPU kostnaden är densamma på alla testade plattformar. Tidigare versioner av den här dokumentationen kopplade samman variationerna på I/O kostnaden till antalet processorer, vilket vi nu vet att det inte är korrekt.
Två andra användbara verktyg är alternativet SET STATISTICS IO och Profiler. STATISTICS IO rapporterar bland annat scannade räkningar och logiska läsningar. Profiler kan rapportera skrivningar och läsningar. Både STATISTICS IOs logiska läsningar och Profilerns läsningar innebär antalet sidor som är lästa från datacachen. Den logiska läsningen kallas också logisk I/O. En sida kan accessas fler än en gång från en given SQL-sats. En intressant sak är att Profilern inte nödvändigtvis visar skriv I/O för UPDATE-, INSERT- eller DELETE-uttrycken.
Testtabeller
För att granska exekveringsplanens kostnadsstruktur så används två typer av testtabeller, vilket visas nedan. Kolumnerna har ingen specifik betydelse annat än ID kolumnen kan definieras som antingen en Clustrad eller icke-Clustrad primärnyckel. I tabellscantesterna definieras ingen primärnyckel. Det enda som specificeras är datatyper av fixerad längd, och det tillåts inga NULL värden. Den första tabellen är designad till att få plats med ett relativt högt antal poster per sida (320 vid en fyllfaktor på 90 %), men färre än det maximala antalet poster som det går. Den andra kolumnen är designad till att få plats med cirka 100 poster per sida, vilket blir 99 poster vid en fyllfaktor på 90 %.
CREATETABLE N1x (
ID intNOT NULL,
Value char(10) NOT NULL )
CREATETABLE M2x (
ID intNOT NULL,
ID2 intNOT NULL,
ID3 intNOT NULL,
ID4 intNOT NULL,
ID5 intNOT NULL,
ID6 intNOT NULL,
GroupID intNOT NULL,
CodeID intNOT NULL,
Value char(10) NOT NULL,
randDecimal decimal(9,4) NOT NULL,
randMoney moneyNOT NULL,
randDate datetimeNOT NULL,
seqDate datetimeNOT NULL )
Det används olika typer och kombinationer av Index för att kunna få fram en specifik exekveringsplan. SQL-sats hints används om de behövs för att tvinga fram en särskild exekveringsplan, så att flera planer till en given SQL-sats kan jämföras. Suffixet visar på primärnyckelns Indextyp. N1C har t ex en Clustrad primärnyckel på ID kolumnen. Och N1N har en icke-Clustrad primärnyckel på ID kolumnen, och tabellen har inget Clustrat Index. N1H har inga Index alls. Varje tabell har kolumner som är fyllda på ett sånt sätt så att alla giltiga sökargument mot den tabellen returnerar samma antal poster, och så att det faktiska antalet poster matchar det beräknade antalet poster så nära som möjligt.
Script för datapopulation
Varje tabell har fyllts med data på ett sånt sätt så att man kan se kostnaden för varje exekveringsplan som en funktion av de involverade posterna och sidorna. Ett exempel på en loopscript visas här nedan.
DECLARE @I int, @rowCnt int
SELECT @I = 1, @rowCnt = 50000
WHILE @I <= @RowCnt BEGIN
INSERT M2C_01 (ID, ID2, ID3, ID4, ID5, ID6, GroupID, CodeID,
Value, randDecimal, randMoney, randDate, seqDate)
VALUES (@I, …)
SET @I = @I+1
END
Nedan visas några av de formler som används för att kunna uppnå en specifik distribution:
1. (@I-1)/10 + 1
2. (@I-1)%(@rowCnt/10) + 1
3. 1 + (@I-1)*100/@rowCnt + ((@I-1)*100)%@rowCnt
4. (@I-1)%(320) + 1
Den första formeln genererar en nummersekvens som ökar med 1 för var tionde värde av @I. Denna distribution används för att fylla GroupID kolumnen, där ett set av siffror från påföljande poster har ett specifikt GroupID värde.
Den andra formeln genererar en sekvens där vanliga värden separeras så långt som möjligt. För t ex en posträkning på 50 000 så finns värdet 1 i den post 1, post 5001, osv. Den här distributionen används till CodeID kolumnen.
I vissa fall så fylls ID2 kolumnen med samma värden som ID kolumnen. En SQL-sats som specificerar ID2 kolumnen får då ut exakt samma värden som om den skulle ha specificerat ID kolumnen. Den här jämförelsen är avsedd att utforska de kostnadsskillnader av exekveringsplanen som beror på unikhetsvillkoren, som garanteras av en primärnyckel eller ett unikt Index.
Den tredje formeln genererar sekvensen 1, 101 … 49901, 2, 102, osv. Varje påföljande värde ökar med 100 och återvänder efter 50 000. Den här sekvensen används till ID3 kolumnen, för JOINs där varje följande post i den andra tabellen lokaliseras i en annan sida (med 99 poster per sida).
Den fjärde formeln är en delfunktion som helt enkelt genererar en sekvens med maxvärdet 320.
Andra formler kan användas vid behov för att generera en specifik distribution.
0 Kommentarer