SQL Server Kvantitetsprestandaanalys #3
Förord
 Varje SQL-sats har en eller flera möjliga exekveringsplaner. En exekveringsplan består av en eller flera komponentoperationer. Genom att granska kostnaden av varje komponentoperation under vissa förutsättningar, så kan man få reda på de funktionella behoven för komponentoperationens plankostnadsformel. Det visar då att kostnadsformeln för varje komponentoperation i SQL Server beror på det antal poster och sidor som är involverade. Den totala beräknade kostnaden för en exekveringsplan kan kalkyleras fram genom att använda komponentoperationens kostnadsformler och de statistiska beräkningarna för de poster och sidor som är involverade i varje komponent. Det här låter Query Optimizern att välja en exekveringsplan. Det kan hända att inte alla möjliga exekveringsplaner granskas när det gäller en komplicerad SQL-sats. De komponentoperationer som granskas här inkluderar Index Seeks, Bookmark Lookups, tabellscans, Nested Loops, Hash- och Merge JOIN operationer samt några andra vanliga operatorer.
Varje SQL-sats har en eller flera möjliga exekveringsplaner. En exekveringsplan består av en eller flera komponentoperationer. Genom att granska kostnaden av varje komponentoperation under vissa förutsättningar, så kan man få reda på de funktionella behoven för komponentoperationens plankostnadsformel. Det visar då att kostnadsformeln för varje komponentoperation i SQL Server beror på det antal poster och sidor som är involverade. Den totala beräknade kostnaden för en exekveringsplan kan kalkyleras fram genom att använda komponentoperationens kostnadsformler och de statistiska beräkningarna för de poster och sidor som är involverade i varje komponent. Det här låter Query Optimizern att välja en exekveringsplan. Det kan hända att inte alla möjliga exekveringsplaner granskas när det gäller en komplicerad SQL-sats. De komponentoperationer som granskas här inkluderar Index Seeks, Bookmark Lookups, tabellscans, Nested Loops, Hash- och Merge JOIN operationer samt några andra vanliga operatorer.
Innehåll
»»
»
»
»
»
»
»
»
»
»
»
»
»
Kostnaden för SQL Serverns exekveringsplan
av Joe Chang
Index Seek
Index Seek är en av de mest grundläggande komponentoperationerna. Exemplet nedan visar på en simpel SQL-sats som returnerar en enda post. Tabellen har ett Clustrat Index på ID kolumnen, så det krävs ingen Bookmark Lookup. Figur 1 visar den grafiska exekveringsplanen och Figur 2 visar detaljerna för Index Seek komponenten.SELECT * FROM N1C WHERE ID = 1
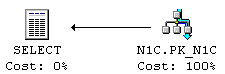
Figur 1: Exekveringsplanen för en SQL-sats med en Index Seek operation
Kostnadsdetaljerna för Index Seek operationen visas nedan.

Figur 2: Detaljer för Index Seek komponenten
Genom att granska kostnadsstrukturen av Index Seek operationen över vissa posträkningar så kan man se att kostnadsformeln för Index Seek operationen blir som följer:
I/O kostnaden = 0.00632850 + 0.000740741 per extra sida (≤1GB)
= 0.003203425 + 0.000740741 per extra sida (>1GB)
CPU kostnaden = 0.0000796 + 0.0000011 per extra post
Själva SELECT komponenten har dessutom en kostnad på 0,0000001 per post, som visas i Figur 3:
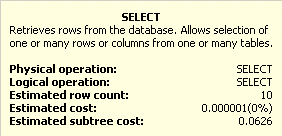
Figur 3: Detaljer för SELECT komponenten
Den första I/O kostnadsformeln gäller för system som har mindre än eller lika med 1 GB i minne. Den andra kostnadsformeln gäller för system som har mer än 1 GB i minne. I/O kostnaden per varje extra sida gäller då många poster returneras (eller granskas om de inte returneras), och då posterna finns på fler än en lövnivåsida. Anta t ex att en lövnivåsida av ett Index innehåller 500 poster. Returnering av upp till 500 poster kräver då ingen extra lövnivåsida, så till vida att inte posterna råkar sträcka sig över två sidor. För varje 5000 poster så krävs ytterligare en sida.
Exekveringsplanens kostnad av Index Seek varierar inte över utsträckningen av Indexet. En liten tabell där hela Indexet får plats på en enda sida har samma exekveringsplanskostnad som en mellanstor tabell med två Indexnivåer (Rot och löv), och som en större tabell med tre eller fler Indexnivåer (Rot, Löv samt en eller flera mellanliggande nivåer).
Bookmark Lookup
Bookmark Lookup är inte något individuell operation, utan föregås alltid utav en Index Seek. Den här operationen inträffar då ett icke-Clustrat används i Index Seek operationen, och då det krävs värden som inte finns i Indexet. I Figur 4 kan du se en exekveringsplan som involverar en Bookmark Lookup, och detaljerna för Bookmark Lookupen kan du se i Figur 5.
Figur 4: En exekveringsplan med Index Seek- och Bookmark Lookup- operationer.

Figur 5: Detaljer för kostnaden av en Bookmark Lookup
Kostnadsformeln för flera Bookmark Lookup operationer kan skådas som formeln nedan:
I/O kostnaden = flertalet 0.00625000 (≤1GB)
= flertalet 0.003124925 (>1GB)
CPU kostnaden = 0.0000011 per post
Kostnadsformeln är densamma oavsett om tabellen har ett Clustrat Index eller är en grupp (heap). Det här är en viktig sak att påpeka eftersom Bookmark Lookup operationer beror på tabellens organisation. Då tabellen är en grupporganisation så innehåller det icke-Clustrade Indexet en pekare till en specifik fil, sida och post, och då tabellen har ett Clustrat Index så innehåller det icke-Clustrade Indexet nyckelvärdet till det Clustrade Indexet. Bookmark Lookup operationen är som en fil-, sid- eller post-Lookup vid en grupptabell, medan den kräver en Index Seek för tabeller med Clustrade Index.
Sammansättningen i Bookmark Lookup operationens kostnadsformel är inte alltid ekvivalent med antalet poster. Sammansättningen är 1 för en enda post. För ett fåtal poster (<20) så är sammansättningen vanligtvis en mindre än det antalet poster som returneras. Då en större mängd poster returneras så kan sammansättningen vara någonstans mellan 64-98 % av det beräknade antalet poster.
Figur 6 visar Bookmark Lookupens I/O kostnadssammansättningen för en tabell med över 500 000 poster i 5 051 8kb sidor, som en procentuell del av antalet involverade poster. Man kan inte se det exakta mönstret för Bookmarksammansättningen, men man kan ofta se en nedåtpik för det mellanliggande antalet poster, vid andra tabellstorlekar. Det förväntas att den egentliga kostnaden beror på hur ofta varje påföljande Bookmark Lookup involverar samma lövnivåsida som den föregående Lookupen. Eftersom det inte finns något sätt för Query Optimizer att avgöra det så kanske kurvan representerar en uppskattning på ett sådant inträffande.
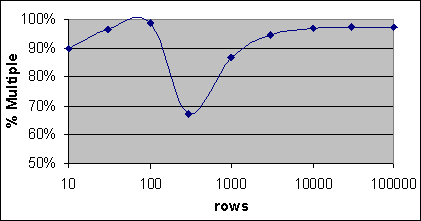
Figur 6: Bookmark Lookupens I/O kostnadssammansättningen som en procentuell del av antalet poster
Bookmarkens I/O kostnad för den enda posten är exakt 0,0000785 mindre än Index Seekens I/O baskostnad (inga extra sidor). En möjlig tolkning kan vara att 0,006250 (<1GB) är kostnaden för att lokalisera och låsa den önskade sidan, att 0,0000785 är kostnaden för att läsa av den sidan samt att 0,0000011 är kostnaden för att låsa och returnera en enda post. Det innebär att ett Index Seek först kräver en lokalisering och läsning av de övre nivåsidorna, med 0,006250 + 0,0000785 för I/O kostnaden, och för det andra kräver en läsning av lövnivåsidan, med 0,0000785 + 0,0000011 för CPU kostnaden. Det här är dock en ren spekulation och det finns flera möjliga tolkningar av det här.
I en Bookmark Lookup för en grupporganiserad tabell så innehåller det icke-Clustrade Indexet en fullständig pekare till filen, till en specifik sida samt till postens Offset (RID), det är därför det bara är I/O kostnaden 0,006250 och postkostnaden 0,0000011 som räknas in. Vid en tabell med ett Clustrat Index så innehåller det icke-Clustrade Indexet nyckelvärdet till det Clustrade Indexet, vilket kan få en att tro att hela kostnaden för Index Seeken ska räknas in. Många källor indikerar på att Bookmark Lookupen på tabellen med det Clustrade Indexet är mer expansivt än Bookmark Lookupen på den grupporganiserade tabellen, medan kostnaden för exekveringsplanen på båda typerna av Bookmark Lookups är identiska.
Tabellscan
En tabellscan operation inträffar då det inte finns några lämpliga Index att tillgå. Det kan innebära att det helt enkelt inte finns några Index alls, eller att det förväntas många poster och att det då är mindre expansivt att scanna hela tabellen. Om det är en grupporganiserad tabell så visar exekveringsplanen en tabellscan, och om tabellen har ett Clustrat Index eller om de värden som krävs finns i ett icke-Clustrat Index så visar exekveringsplanen en Indexscan operation. Du kan se detta i Figur 7.
Figur 7: Exekveringsplaner för tabellscan- och Clustrade Indexscanoperationer
Figur 8 och 9 visar kostnadsdetaljerna för tabellscan- och Indexscanoperationerna. Ett Indexscan har samma kostnadsstruktur som en tabellscan.
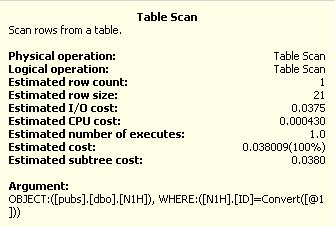
Figur 8: Kostnadsdetaljer för tabellscannen

Figur 9: Kostnadsdetaljer för den Clustrade Indexscannen
Genom att granska I/O och CPU kostnaderna för tabeller över ett område av sidor och poster så blir kostnadsformeln för exekveringsplanen som följer:
I/O kostnaden = 0.0375785 + 0.000740741 per extra sida
CPU kostnaden = 0.0000785 + 0.0000011 per post
Baskostnaden för I/O (0,0375785) är exakt 6 x 0,0062500 + 0,0000785. Ingen av tabellscannens kostnadskomponenter verkade variera över plattformer (1P/2P/4P).
Kostnadsöverslag vid Index Seek och tabellscan
Det kan bara finnas ett Clustrat Index i varje tabell, och det är inte alltid praktiskt att skapa ett täckande Index för varje SQL-sats som inte behöver det Clustrade Indexet. Då skulle det finnas SQL-satser där exekveringsplanen antingen kommer att vara 1) ett Index Seek med en Bookmark Lookup, eller 2) en tabellscan (eller en Clustrad Indexscan). Då man räknar med få poster från sökargumentet så kommer exekveringsplanen att bli ett Index Seek med en Bookmark Lookup. Då man räknar med att returnera många poster så kommer exekveringsplanen att vara en tabellscan. Det kan vara användbart att veta exakt när exekveringsplanen byter från det ena till det andra. 
Kostnaden av en tabellscan kan bestämmas genom antalet sidor som tas upp av tabellen samt det totala antalet poster som finns i tabellen. Kostnaden av en tabellscan är inte beroende av antalet poster som returneras (så till vida att det inte finns en förminskningsfunktion involverad). Kostnaden av en Index Seek operation beror endast på antalet poster som returneras samt av antalet lövnivåsidor av Indexet som de valda posterna tar upp, men inte på den absoluta storleken av tabellen (vilken bidrar till Indexets omfattning). Kostnaden av Bookmark Lookup operationen påverkas av tabellens storlek (av den obestämbara mångfalden), men är relativt linjär med antalet involverade poster.
Överslaget, där en tabellscan blir mindre expansiv än en Index Seek med en Bookmark Lookup, kan avgöras genom att jämföra de två exekveringsplanernas kostnadsformler. Genom att ange Bookmark Lookup operationens kostnadssammansättningen som en korrektionsfaktor (CF) och bortse från vissa mindre betydelsefulla kostnadskomponenter, så kan man bestämma den ungefärliga tvärsnittspunkten.
Skillnaden mellan uppstartningskostnaderna för de två olika exekveringsplanerna är ungefär kostnaden för 5 Bookmark Lookup operationer för 1P/2P systemen, eller 11 operationer i 4P systemet. Kostnaden för varje ökande post i en Bookmark Lookup är en mångfald av 0,0062511 för 1P/2P systemen och 0,0031260 för 4P systemet, och då är både I/O kostnaden och CPU kostnaden inräknad. Kostnaden för varje extra sida i tabellscannen är 0,000740741 + 0,0000011 x (poster per sida). Tvärsnittspunkten blir ungefär enligt formlerna nedan, relaterat till antalet poster som möter villkoren för Indexsökningen, samt antalet sidor i tabellen (enligt kvoten sidor-per-post) och korrektionsfaktorn CF. Kvoten sidor-per-post är helt enkelt antalet sidor, där den progressiva kostnaden i tabellscannen är lika med kostnaden för en Bookmark Lookup. Korrektionsfaktorn CF är den procentuella mångfalden av kostnaden för Bookmark Lookupen.
Poster ~ 5 + Sidor / (CF×(kvoten sidor-per-post)) (1P & 2P)
~ 11 + Sidor / (CF×( kvoten mellan sidor-per-post)) (4P)
Eftersom kostnaden av en progressiv sida i tabellscannen beror på antalet poster per sida, så blir kvoten sidor-per-post en funktion av samlingen av poster per sida. Det här beroendet visas i Figur 11 här nedan.
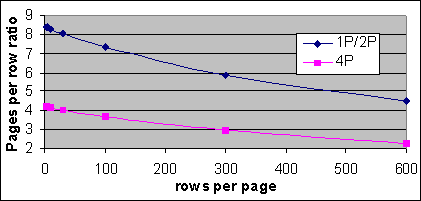
Figur 11: Kvoten sidor/post kontra samlingen av poster/sida
Tänk dig t ex en tabell med en genomsnittlig samling av 100 poster per sida. Kvoten sidor-per-post blir då 7,35 för 1P/2P systemen, och korrektionsfaktorn ~0,90. För en tabell med 506 sidor så kommer det beräknade kostnadsöverslaget att uppstå vid cirka 81,5 poster, jämfört med den faktiska överslagspunkten vid 84 poster. Med andra ord så bör Indexselektiviteten vara bättre än 1 post för varje 0,9*7,35 sidor i tabellen, för att Query Optimizer ska kunna använda Indexet då en Bookmark Lookup krävs, istället för en tabellscan. Det kan dock finnas en viss skillnad vid punkten då överslaget av kostnad sker och då planen byter av.
Figur 12 visar exekveringsplanskostnaden för ett Index Seek och en Bookmark Lookup som en funktion av poster, samt kostnaden för en tabellscan för 50 000 poster vid 99 poster per sida. Kostnaden för tabellscannen är inte beroende av antalet poster som returneras.
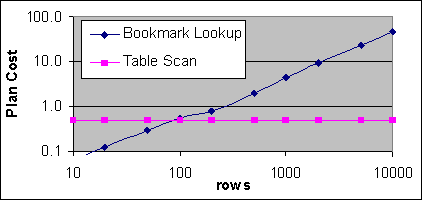
Figur 12: Plankostnader för en tabell med 50 000 poster och 99 poster per sida
Diagrammet i Figur 13 visar en vanlig graf plankostnaderna för Index Seeken och Bookmark Lookupen i 1P/2P och 4P systemen som en funktion av involverade poster, samt plankostnaden för tabellscannen som en funktion av antalet sidor i tabellen (förutsatt att det finns 100 poster per sida). Jämförelsevis visas och kostnaden av den täckande Indexsökning som en funktion av antalet involverade poster. Om man vet storleken på tabellen i antalet sidor så kan man avgöra kostnadsöverslaget för Bookmark Lookup-tabellscan genom att finna antalet poster där kostnaden för Bookmark Lookup planen har samma kostnad som tabellscan-planen, och vice versa.
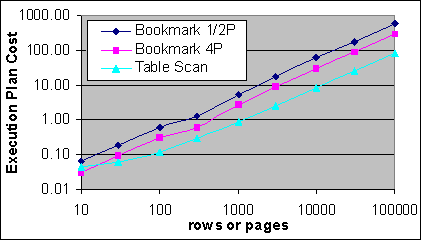
Figur 13: Plankostnader kontra poster/sida
Som ett resultat av I/O kostnadsskillnaderna för 1P/2P systemens och 4P systemets Index Seek och Bookmark Lookup, så krävs det ungefär dubbelt så många Bookmark Lookups i 4P systemet för att nå överslagspunkten för en tabellscan, jämfört med 1P/2P systemen. Givet att många multiprocessorsystem använder en gemensam buss, så verkar det resonabelt att vänta med att byta till en högre bussbandbredd, såsom en tabellscan, på 4P systemet jämfört med 1P/2P systemen. Det är inte självklart att det här är förklaringen.
Vid höga posträkningar så är plankostnaden för en Bookmark Lookup 700 gånger högre än den täckande Indexsökningen i 1P/2P systemen, och 350 gånger högre i 4P systemet. I det här exemplet så innefattar det täckande Indexet lite drygt 400 poster per sida.
Notera att plankostnaderna för det täckande Indexet och tabellscannen är väldigt plana vid låga posträkningar. Det beror på att kostnaden för extra poster är väldigt låg jämförbart med den fixerade baskostnaden för Indexsökningen och tabellscannen. Faktum är att det krävs 800 poster för att fördubbla kostnaden av en täckande Indexsökning vid 100 poster per sida, baserat på kostnadsformeln i 1P/2P, och 400 poster baserat på kostnadsformeln i 4P. För att fördubbla kostnaden av en tabellscan av en enda post så krävs det en tabellscan av 4 500 poster i 45 sidor.
Summeringar
Stream Aggregate och Compute Scalar operationer inträffar i summeringsfunktioner (MIN, MAX, COUNT, AVG eller SUM), vilket visas i SQL-satsen här nedan.
SELECT COUNT(*), AVG(Value) FROM M2C_10
Funktionerna MIN och MAX kräver Stream Aggregate operatorn. De andra funktionerna kräver en Stream Aggregate operator följt av en eller flera Compute Scalar operatorer i exekveringsplanen.
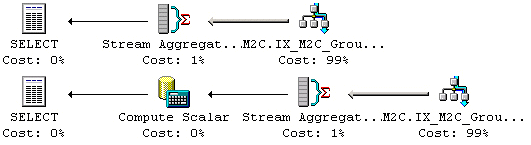
Figur 14: En exekveringsplan som involverar summeringar och Compute Scalar

Figur 15: Kostnadsdetaljer för Stream Aggregate operationen

Figur 16: Kostnadsdetaljer för Compute Scalar operationen
Båda operatorerna listar en CPU kostnad på 0,0000001 per post (ingen I/O kostnad), men det verkar som om det bara är en av dem som ska räknas med i den slutgiltiga kostnaden.
JOINs
Det finns tre huvudsakliga former av JOIN operationer i SQL Server: Nested Loops (Loop), Hash och Merge. Nested Loops JOIN uppstår ofta i transaktionshanterande applikationer, där SQL-satserna vanligtvis involverar några rader från varje tabell. Hash och Merge JOINs uppstår frekvent i applikationer med bestämmande support, där JOINs ofta påverkar många poster. Det finns egentligen tre former av Hash JOINs. Den Hash JOIN som vi undersöker här in-memory Hash JOIN, där hela Hashtabellen får plats i minnet. De andra två formerna av Hash JOINs används till väldigt stora datastrukturer, vilka inte kan passas in i det tillgängliga minnet. Query Optimizern avgör vilken typ av JOIN, samt vilken ordning på JOIN, som är den mest effektiva. Om en särskild typ av JOIN (Loop, Hash eller Merge) är specificerad så är också JOIN ordningen fastställd.
Nested Loops JOIN
SQL-satsen nedan visar en simpel JOIN mellan två tabeller. Exekveringsplanen för en SQL-sats kan innefatta Indexsökningar, Bookmark Lookups, eller tabellscans, beroende på det specificerade sökargumentet samt vilka Index som finns att tillgå.
SELECT M2C_01.ID, M2D_01.Value
FROM M2C_01 INNER JOIN M2D_01 ON M2D_01.ID = M2C_01.ID2
WHERE M2C_01.GroupID = 1
I SQL-satsen ovan har tabellen M2C_01 ett täckande Index på kolumnerna GroupID, ID och ID2 (vilka kan inkluderas automatiskt om ID är en del av – eller hela – en Clustrad primärnyckel), och där tabellen M2D_01 har ett Clustrat Index på ID kolumnen. Loop JOINens exekveringsplan (som du kan se i Figur 17) har den lägsta plankostnaden vid låga posträkningar.
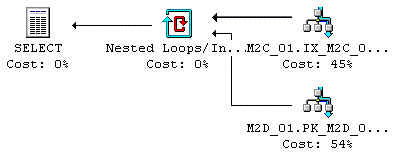
Figur 17: Exekveringsplanen vid en Loop JOIN
Den övre tabellen (M2C_01) i ovanstående exekveringsplan är den yttre källan, medan den undre tabellen (M2D_01) är den inre källan. Kostnadsdetaljerna för de tre komponenterna i ovanstående Nested Loop JOIN visas i Figur 18, 19 och 20. Loop JOIN planen returnerar först poster från den yttre källan. För varje post från den yttre källan kan man finna alla matchande poster från den inre källan. Trots att det inte har specificerats något specifikt sökargument för den inre källtabellen så kan själva JOIN villkoret användas som sökargument i en Nested Loops JOIN. I det här exemplet returneras tio poster från den yttre källan där detaljerna visas den uppmätta posträkningen (= 10) och den uppmätta antalet exekveringar (= 1).

Figur 18: Kostnadsdetaljer för Index Seek från den yttre källan

Figur 19: Kostnadsdetaljer för Index Seek från den inre källan

Figur 20: Kostnadsdetaljer för Loop JOIN
Varje post från den yttre källan matchar exakt en post från den inre källan. Detaljerna för den inre källans Indexsökningsoperation indikerar på en uppmätt posträkning på 1 och det uppmätta antalet exekveringar till 9,919 (egentligen 10). Detaljerna för Nested Loops/INNER JOIN visar en uppmätt posträkning på 9, medan SET alternativet SHOWPLAN_ALL avslöjar att det egentligen är 9,92. Den kostnadsdetaljen rundar av nedåt, istället för att runda av till det närmaste värdet. Notera att argumentet i Loop JOIN detaljen är OUTER REFERENCES. Det väsentliga i det diskuteras senare.
Då den yttre källan är en Indexsökningsoperation (och inte en Bookmark Lookup) så är kostnaden för den här komponenten samma kostnad som den Indexsökningsoperationen som vi diskuterade tidigare. Loop JOINens komponentoperation med argumentvillkoret OUTER REFERENCES har ingen I/O kostnad, medan CPU kostnadsformel blir som följer:
Loop JOINens CPU kostnad = 0.00000418 per post
Kostnadsdetaljen för den inre källtabellen visar att I/O kostnaden och CPU kostnaden är densamma som för en Index Seek för en enda post (0,0063285 och 0,0000796), medan kostnaden för hela operationen (som har exekverats 9,919 gånger) är 0,00768413. Kostnadsformeln kontra antalet exekveringar är inte så enkel som summan av I/O kostnaden och CPU kostnaden multiplicerat med antalet exekveringar.
Faktum är att man har observerat tre olika beteenden vid kostnaderna kontra posträkningarna för den inre källans Loop JOIN, och det kan demonstreras genom de tre SQL-satserna som visas här nedan, vilka involverar en JOIN mellan två tabeller. (Det finns också ett fjärde fall som involverar en Spooloperation). Här är en Loop JOIN är helt enkelt specificerad vilket, framtvingar en JOIN ordning med den första tabellen som den yttre källan, och den andra tabellen som den inre källan. Den yttre källtabellen har i alla tre fall ett täckande Index som börjar med GroupID kolumnen och följs av JOIN kolumnen.
Fall 1:
SELECT M2C_01.ID, N1C_01.Value
FROM M2C_01 INNER LOOP JOIN N1C_01 ON N1C_01.ID = M2C_01.ID6
WHERE M2C_01.GroupID = @Group1
Fall 2:
SELECT M2C_01.ID, M2D_01.Value
FROM M2C_01 INNER LOOP JOIN M2D_01 ON M2D_01.ID = M2C_01.ID2
WHERE M2C_01.GroupID = @Group1
Fall 3:
SELECT M2C_01.ID, M2D_01.Value
FROM M2C_01 INNER LOOP JOIN M2D_01 ON M2D_01.ID = M2C_01.ID2
WHERE M2C_01.GroupID = @Group1 AND M2D_01.GroupID = @Group2
Det finns ingen logisk skillnad mellan det första och andra fallet. Den enda skillnaden är storleken på de inre källtabellerna. I Fall 1 så är N1C_01 tabellen liten och platsar på en enda 8kb sida. I Fall 2 så är N1D_01 tabellen inte lika liten med sina 50 000 poster och 506 sidor. Den yttre tabellen (M2C_01) råkar också ha 50 000 poster, men det påverkar inte kostnadsstrukturen. JOINarna i både Fall 1 och Fall 2 använder det Clustrade Indexet till Indexsökningsoperationen för den inre källan. I Fall 3 används samma tabell som i Fall 2. Skillnaden mellan dessa två är att man i Fall 3 specificerar ett specifikt sökargument för den inre källtabellen. Det här låter den inre källans Index Seek använda ett Clustrat Index som börjar med GroupID kolumnen och följs av JOIN kolumnen.
Titta nu på hur Loop JOINen ser ut. För varje post från den yttre källan så matchas en post från den inre källan. Det finns ingen garanti på att varje påföljande post i den yttre källan matchar de påföljande posterna i den inre källan. Den första posten från den yttre källan kan t ex ha ett JOINat kolumnvärde på 1, medan nästa post kan vara 2 eller 50 000. Varje post från den yttre källan kräver en fulländad Indexsökningsoperation för att kunna lokalisera matchande värden från den inre källan. Det enda som är säkert är att den rotnivå av Indexet som används till den inre källtabellen redan har hittats.
Figur 21 visar exekveringsplanerna för de normaliserade kostnaderna av Fall 1, 2 och 3 för Loop JOIN-SQL-satserna i exemplet ovan. Den ”normaliserade kostnaden” är kostnaden dividerat med Indexsökningskostnaden för en enda post (0,0064081 för 1P/2P). 4P kostnaden har i grund och botten samma kostnadsstruktur förutom att baskostnaden för en Index Seek i runda tal är hälften av kostnaden i 1P/2P. Alla tre fall har samma kostnader för den yttre källindexsökningen och Loop JOIN komponenten, så den enda skillnaden som finns är kostnaden för den inre källindexsökningen.
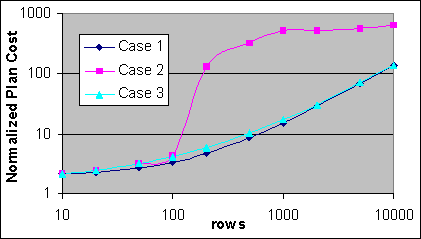
Figur 21: Loop JOIN kostnaden kontra posträkningen
I Fall 1 så får hela den inre källtabellen plats på en enda sida så involverar den inre källans exekveringsplan helt enkelt upprepade läsningar från en lövnivåsida för varje post från den yttre källan. Den inre källans kostnadsformel i Fall 1 är då väldigt lik följande:
Kostnaden för den inre källan i Fall 1 = 0.0063285 + 0.0000796 per exekvering
I exemplet med Fall 2 så är inte den inre källtabellen liten. Kostnadsformeln vid relativt få exekveringar blir då som följande:
Kostnaden för den inre källan i Fall 2 = 0.0063285 + 0.000140-0.000154 per exekvering
När det gäller större posträkningar så skiljer sig kostnadsformeln rejält från ovanstående ekvation. I Fall 3 så är den inre källtabellen inte liten, men det täckande Indexet isolerar ett visst område av poster i den inre källan. Kostnadsformeln för den inre källan i Fall 3 liknar kostnaden i Fall 2 vid ett lågt antal poster, men det visar inte det enorma hoppet som sker mellan 200 och 300 poster.
Figur 22 visar den normaliserade differentialkostnaden per post för de tre Loop JOINs som vi har diskuterat ovan. Den differentiella kostnaden per post vid 300 poster kan räknas ut genom att ta kostnadsskillnaden mellan JOINen vid 300 poster och JOINen vid 100 poster, och dividera det med postskillnaden (200).
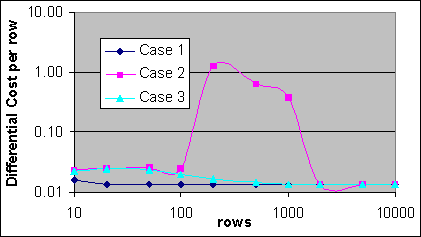
Figur 22: Differentialkostnaden för Loop JOIN per post
SQL-satsen i Fall 1 har en kostnadsformel som är väldigt lik den ovan beskrivna (0,0000796 för varje påföljande exekvering i den inre källtabellen). SQL-satserna i både Fall 2 och 3 har ungefär samma kostnadsformel vid ett lågt antal poster, på cirka 0,00015 per post i den inre källkomponenten. Någonstans mellan 100 och 200 poster så hoppar den inre källkostnaden i Fall 2 rejält. Med det här så kan vi slutligen se att vid ett högt antal poster (i det här fallet ~1000-2000 poster) så är den påföljande exekveringen i alla tre fall 0,0000796 per exekvering av den inre källan. Kostnadsstrukturen i Fall 3 minskar gradvis från området i Fall 2 till området i Fall 1. Det är möjligt att den påverkan som Fall 3 har på den dubbelt explicita SARGen endast är fördelaktig under ett begränsat antal omständigheter.
Ovanstående plankostnadsdiagram är för en-till-en JOINs, där varje post från den yttre källan relateras till exakt en post från den inre källan. Då varje post från den yttre källan har relaterat till en eller flera poster från den inre källan så blir den påföljande CPU kostnaden för den inre källan (vilket är en kostnad per exekvering):
CPU kostnaden för den inre källan = 0.0000011 per extra post
Tydligen är det så att om varje post från den yttre källan matchar ett stort antal poster i den inre källan, så tillkommer även kostnaden 0,00074074 per extra lövnivåsida, men det här villkoret har inte testats ännu. Kostnaden för Loop JOIN komponenten (0,00000418) tillkommer även alla poster från JOINen.
Loop JOINs kan involvera Bookmark Lookup operationer för antingen den inre eller yttre källan, eller båda två. Den första exekveringsplanen i Figur 23 visar att en Bookmark Lookup operation sker före JOIN operationen för den yttre källan. Den andra planen visar att en Bookmark Lookup sker efter JOIN operation för den inre källan. En Bookmark Lookup kan inträffa antingen före eller efter JOIN operationen. Kostnaden för en Bookmark Lookup verkar följa de regler som vi fastställde tidigare, men detta har inte undersökts så djupt ännu. Man har dock observerat sporadiska kostnadsvariationer. Den yttre källan kan också vara en tabellscanoperation och det är inte alls troligt att en Loop JOIN hade en tabellscan för den inre källan, eftersom det skulle ske en gång för varje access som den yttre källan gör.
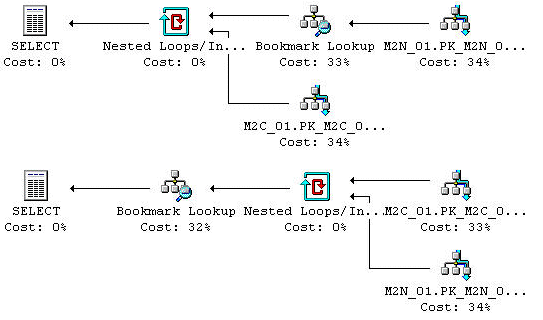
Figur 23: Loop JOINs med Bookmark Lookup
Man kan summera kostnadsstrukturen för en Loop JOIN så här. Den yttre källans kostnadskomponent följer de formler som resulterades tidigare för Indexsökningar och Bookmark Lookups (om det krävs) eller en tabellscan. Den inre källan är lite mer komplicerad. Om man inte har specificerat någon specifik SARG så kan den påföljande kostnaden per post vara antingen relativt låg eller relativt hög. Komponentoperationen för en Loop JOIN är dock relativt simpel eftersom den bara har en CPU kostnad per post.
Om man bara har specificerat sökargument till en enda tabell så kan man (genom att använda den tabellen som den yttre källan) eliminera den höga kostnadsarbetslasten från tabellscannen. Ett Index på JOIN kolumnen i den inre källtabellen kan användas i en Loop JOIN. Om man har specificerat sökargument för den inre källtabellen så kommer ett Index på SARG (följt av JOIN kolumnen) inte att ha de ovanligt höga kostnaderna per post i mitten av posträkningsområdet. Den andra faktorn som kan påverka JOIN ordningen är antalet involverade poster från varje tabell. Kostnadsstrukturen per post för en Loop JOIN föredrar tabellen med få poster som den yttre källan.
Hash JOINs
Både Hash och Merge JOINs hanterar den yttre och inre källan separat. JOIN villkoret kan inte användas som ett sökargument. Om det inte finns något särskilt sökargument specificerat för någon av tabellerna, eller om det inte existerar några passande Index, så krävs det en scan över den tabellen. Det är möjligt att Hash- och Merge JOIN-operationer kan Bookmark Lookup operationer, men det är inte särskilt troligt, så till vida att inte JOIN typen tvingas fram.SQL-satsen nedan skapar specifikt en Hash JOIN. Det skapas sökvillkor för varje tabell i JOIN operationen och det existerar antingen Clustrade eller täckta Index för båda tabellerna.
SELECT m.ID, n.Value
FROM M2C m INNER HASH JOIN M2D n ON n.ID = m.ID
WHERE m.GroupID = @Group1 AND n.GroupID = @Group2
Exekveringsplanen i Figur 24 visar en Index Seek operation för varje källa, samt Hash JOIN operationen, för totalt tre komponenter. Kostnadsdetaljerna för Hash JOIN operationen ser du i Figur 25.
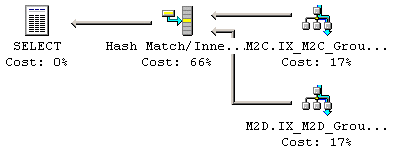
Figur 24: Exekveringsplan för Hash JOIN

Figur 25: Kostnadsdetaljer för Hash JOIN
Hash och Merge JOINens kostnadsstruktur för både den inre och yttre källan ser ut som den för Index Seek och tabelscanoperationerna som beskrevs tidigare. Både de inre och yttre källoperationerna behandlas i en enda exekvering av de involverade posterna till skillnad från den inre källan i Loop JOINen, som exekveras en gång per post från den yttre källan. Kostnadsstrukturen för komponentoperationen i Hash JOIN liknar följande formel:
CPU kostnaden = ~0.017770 + ~0.00001881 per post, 1-till-1 JOIN
+ 0.00000523 till 0.000000531 per extra post i den inre källan
Den första raden används till en 1-till-1 JOIN. Den andra raden används då en post från den yttre källan JOINar fler än en post från den inre källtabellen. Den här kostnadsstrukturen per post föredrar också att ha den tabellen som ger färre poster som den yttre källan. Den totala kostnaden av ovanstående Hash JOIN är summan av den yttre källindexsökningen, den inre källindexsökningen och Hash JOINen.
Merge JOINs
Detaljerna av en Merge JOIN finns diskuterade i SQL Serverns dokumentation samt i andra källor. Det finns två former av Merge JOINs; en-till-många (inkluderar även en-till-en) Merge JOIN och många-till-många Merge JOIN. Båda dessa former av Merge JOINs kräver att posterna från varje tabell är sorterade. En-till-många JOINen är den enklaste och mest effektiva operationen. Det ytterligare huvudkravet vid en en-till-många Merge JOIN är att posterna från den yttre tabellen måste vara unika på JOIN kolumnen. Varje post från den yttre källan kan JOINa hur många poster från den inre källan som helst, men varje post från den inre källan kan bara JOINa en post från den yttre källan. En många-till-många Merge JOIN kräver inte att dessa villkor uppfylls, utan är en lite mer komplicerad operation.SQL-satsen nedan skapar specifikt en Merge JOIN, vilket också tvingar fram en JOIN ordning. Den yttre källan (M2C) har ett täckande Index på GroupID och ID kolumnerna. JOIN kolumnen på den yttre källan är ID fältet, vilket är primärnyckeln, så det möter upp villkoret för en-till-många Merge JOINen. Det finns ett specifikt sökargument specificerat på båda tabellerna, vilket möjliggör en Indexsökningsoperation på både den inre och yttre källan istället för en tabellscan. Båda tabellerna har Clustrade eller täckande Index, så det krävs ingen Bookmark Lookup.
SELECT m.ID, n.Value
FROM M2C m INNER MERGE JOIN M2D n ON n.ID = m.ID
WHERE m.GroupID = @Group1 AND n.GroupID = @Group2
Exekveringsplanen för Merge JOINen visas i Figur 26, medan Figur 27 visar detaljerna för Merge JOINen. Notera att argumentationsobjektet nedan är MERGE. Kostnadsstrukturen för den här Merge JOINen är sammansatt av tre komponentoperationer; två Indexsökningsoperationer (en för den inre och en för den yttre källan) och Merge JOIN komponenten. Kostnadsstrukturen för Indexsökningsoperationen vet vi redan.
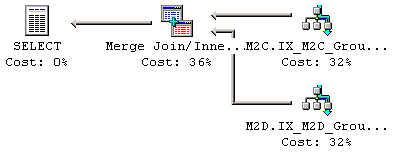
Figur 26: Exekveringsplan för Merge JOIN

Figur 27: Kostnadsdetaljer för Merge JOIN
Kostnadsstrukturen för Merge JOIN komponenten är ungefär följande:
CPU kostnaden = ~0.0056046 + ~0.00000446 per post, en-till-en
Det finns en liten variation i kostnadsformeln från fall till fall. För en en-till-många JOIN så blir kostnaden för varje extra post i den inre källan så här:
CPU kostnaden = 0.000002370 per extra post i den inre källan
Som med alla former av JOINs så föredras den tabellen som ger färre poster som den yttre källan, och den tabellen som ger lite fler poster som den inre källan.
Många-till-många Merge JOINs
I SQL-satsen nedan så är JOIN kolumnen för den yttre källan ID2 kolumnen, som inte är primärnyckel och som inte har något unikt Index på kolumnen. Trots att JOIN villkoret för den andra tabellen är unikt så tvingar den specifika Merge JOINen fram en specifik JOIN ordning, med den första tabellen som den yttre källan. Därför kräver den här SQL-satsen en många-till-många Merge JOIN. Exekveringsplanen för många-till-många Merge JOINen visas i Figur 28, och detaljerna för JOINen visas i Figur 29.
SELECT m.ID, n.Value
FROM M2C m INNER MERGE JOIN M2D n ON n.ID = m.ID2
WHERE m.GroupID = @Group1 AND n.GroupID = @Group2
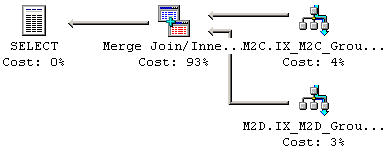
Figur 28: Exekveringsplan för en många-till-många Merge JOIN

Figur 29: Kostnadsdetaljer för en många-till-många Merge JOIN
I/O kostnaden här är inte noll och argumentet är MANY-TO-MANY MERGE. Genom att analysera kostnaden över ett område av poster så kan man observera följande kostnadsformel för komponentoperationen av många-till-många JOINen:
I/O kostnaden = 0.000310471 per post
CPU kostnaden = 0.0056000 + 0.00004908 per post, 1-1
Outputen från STATISTICS IO kommer att visa närvaron av många-till-många Merge med en ’Worktable’ före de två tabeller som är involverade som en del av IO summeringen:
Table 'Worktable'. Scan count 749, logical reads 1250, physical reads 0, read-ahead reads 0.
Merge JOINs med sorterinsoperation
En Merge JOIN operation fulländas med en sorts operation där Indexet inte finns tillgängligt. Figur 30 visar en exekveringsplan där Indexet på den inre källan isolerar de begärda posterna, men som inte finns med i sorteringen som är specificerad JOIN villkoret. Sorteringsoperationens kostnadsdetaljer visas i Figur 31. I Figur 32 kan ni se sorteringens CPU kostnad kontra posterna. Mönstret i sorteringens CPU kostnad är lite krångligare att urskilja. Man kan se att när man har subtraherat bort kostnaden på 0,0000785 så är den kostnad som återstår på graphen i en log-log skala linjär, men med en ökning på lite mer än 1. Någonstans över 5 000 poster så verkar sorteringens CPU kostnad ändra lite på sitt beteende, men det har ännu inte utforskats något närmare. 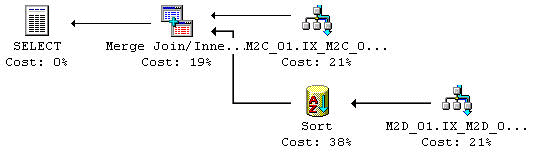
Figur 30: Exekveringsplan för en Merge JOIN med sorteringsoperation

Figur 31: Kostnadsdetaljer för sorteringsoperationen
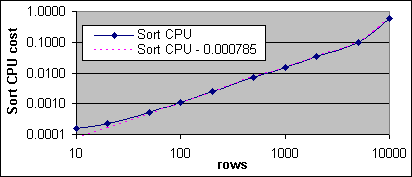
Figur 32: Sorteringsoperationens CPU kostnad kontra poster
Sorteringsoperationens kostnad blir ungefär enligt formeln nedan under upp till 5 000 poster. Mellan 5 000 och 10 000 poster uppstår ett rejält hopp.
Sorteringens I/O kostnad = 0.011261261
Sorteringens CPU kostnad » 0.0000785 + 0.000005 * (poster ^ 1.16)
Sorteringens CPU kostnadsformel är inte linjär. Alltså, sorteringskostnaden per post ökar med antalet poster som ska sorteras.
Jämförelser av Loop, Hash och Merge JOINs
Efter att ha analyserat kostnadsformlerna för Loop, Hash och Merge JOINernas exekveringsplaner individuellt så ska vi nu jämföra dessa tre JOINs sida vid sida, där kraven från varje form av JOIN möts.Figur 33 här nedan visar uppstartningskostnaderna för Loop, Hash och Merge JOINs i 1P/2P. Uppstartningskostnaderna för de inre och yttre källorna representerar baskostnaderna för Index Seek, exklusive kostnaden per post på 0,0000011. JOIN kostnaden exkluderar också den första posten och är endast ungefärlig, eftersom det finns en viss kostnadsvariation från fall till fall. Uppstartningskostnaderna i 4P skiljer sig enbart i baskostnaderna för Index Seek (0,003283025).
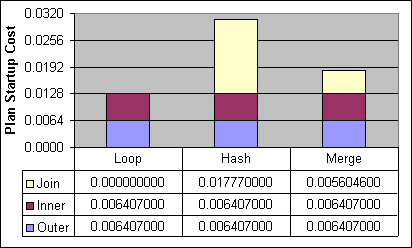
Figur 33: Loop, Hash och Merge JOINs uppstartningskostnader för 1P/2P Index Seek
Tabell 1 nedan visar kostnaderna per post och per sida, för komponenterna i en-till-en Loop, Hash och Merge JOINerna, med specifika SARG på båda tabellerna. Kostnaderna per post (/p) gäller för alla poster, medan kostnaderna per sida (/s) endast gäller om det krävs extra lövnivåsidor. Formlerna för den totala kostnaden per post och per sida måste räkna in villkoren för ”per sida”.
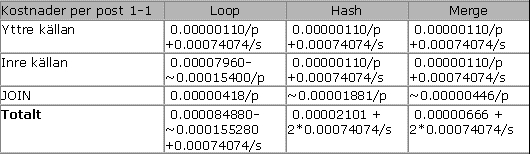
Tabell 1: Komponentkostnadsformler för extra poster i JOIN
Tabell 2 nedan visar de beräknade totala kostnaden per post vid 10 och 100 poster per sida, där kostnaden för extra lövnivåsidor ingår.

Tabell 2: Komponentkostnadsformler för extra poster i JOIN
Loop JOINen har den lägsta fixerade uppstartningskostnaden. Det beror på att själva komponentoperationen i Loop JOIN inte har någon, medan Hash och Merge JOIN komponenterna har en baskostnad på ~0,017770 respektive ~0,0056046.
De yttre källkostnaderna är desamma i alla tre JOINs, vilket är samma som för en Index Seek operation. Skillnaderna i kostnadsstrukturen per post för alla tre former av JOINs kommer mestadels från den inre källan, men också delvis från själva JOIN komponentoperationen. Kostnadsstrukturen i den inre källan för Loop JOINen reflekteras upprepade gånger i Index Seek operationerna. Kostnadsstrukturen för den inre källan i Hash och Merge JOINs är helt enkelt samma som för Index Seek operationen. Kostnaden per post i själva JOIN komponenten har Loop JOIN som lägsta, tätt följt av Merge JOIN och Hash är cirka fyra gånger högre än Loopen.
Den här kostnadsstrukturen resulterar i att Loop JOIN har den lägsta plankostnaden för ett lågt antal poster. Merge JOIN har den lägsta totala kostnaden per post följt av Hash JOIN, medan Loop JOIN har den högsta totala kostnaden per post. Merge JOIN har alltid en lägre plankostnad är Hash JOIN. Vid vissa mellanliggande posträkningar så blir Merge JOIN mindre dyr än Loop JOIN. Vid högre posträkningar blir även Hash JOIN mindre dyr än Loop JOIN. Fördelarna med Hash och Merge JOIN är störst för Index med hög densitet (räknat i poster per sida). När densiteten (i poster per sida) blir lägre så drar den inre källans kostnad per sida ner på fördelarna för Hash och Merge JOINs.
Tabell 3 visar kostnaden per post för extra sidor i den inre källan.

Tabell 3: Den inre källans kostnader för extra poster
Notera att komponenten per sida för Loop JOIN endast skulle gälla om varje post från den yttre källan relaterar till tillräckligt många poster från den inre källan för att kunna kräva extra lövnivåsidor, medan komponenten per sida för Hash och Merge JOIN gäller då den totala summan av poster i den inre källan kräver extra lövnivåsidor. Om det skulle vara en stor skillnad i antalet poster från varje tabell så skulle fördelarna med Hash och Merge JOIN gå förlorade, eftersom Loop JOIN då skulle ha den lägsta kostnaden per post i den inre källan.
Figur 34 och 35 visar den totala normaliserade kostnaden i 1P/2P systemen för Loop, Hash och Merge JOINs, där det specifika sökargumentet är specificerat för både de inre och yttre källorna, där det finns lämpliga Index på varje tabell, samt där varje post från den yttre källan relateras till exakt en post från den inre källan. Kostnaderna för SQL-satsen är förhållandevis graderade till 1P/2P systemens kostnad för en Index Seek mot en enda post (0,0064081).
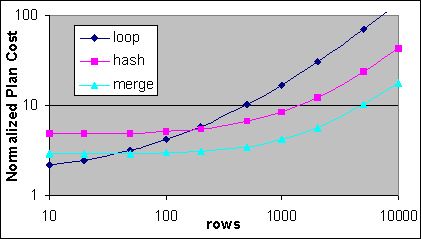
Figur 34: Den totala 1P/2P kostnaden för Loop, Hash och Merge JOINs (Log skala)
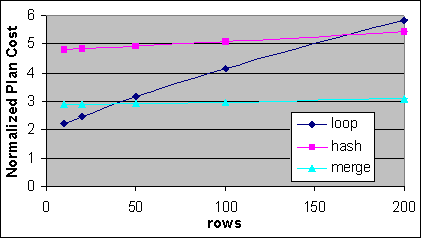
Figur 35: Den normaliserade 1P/2P kostnaden för Loop, Hash och Merge JOINs (linjär skala)
Själva komponentoperationen för Loop JOIN har ingen uppstartningskostnad. De enda uppstartningskostnaderna som finns är för Index Seek operationerna och för de inre och yttre källtabellerna, därför är den totala kostnaden lite drygt dubbla Index Seek operationens vid låga posträkningar. Hash JOIN operationen har en uppstartningskostnad på lite mindre än 3 gånger Index Seek i 1P/2P för en total uppstartningskostnad av lite mindre än 5 gånger Index Seek operationens. Merge JOIN har en uppstartningskostnad på lite mindre än en enda Index Seek i 1P/2P för en total uppstartningskostnad av lite mindre än 3 Indexsökningar. När lämpliga Clustrade eller täckande Index finns tillgängliga på båda tabellerna så är Merge JOIN att föredra över en Loop JOIN vid 40 poster, och Hash JOIN att föredra över en Loop JOIN vid cirka 160 poster. I det här exemplet så använder exekveringsplanen kompakta täckande Index med hög densitet, vilka innefattar mer än 400 poster per sida. Överslagspunkten är högre vid Index med låg densitet.
Figur 36 visar kostnaderna för Loop, Hash och Merge JOINs i 4P. I 4P så finns det en viss skillnad av överslagspunkt mellan Loop, Hash och Merge JOINs jämfört med 1P/2P systemet. På en 4P Server så är I/O baskostnaden för Index Seek cirka halva kostnaden i 1P/2P systemet. Baskostnaderna för Hash och Merge JOINs ändras inte mellan 1P/2P och 4P systemen, så uppstartningskostnaderna är lägre på den absolut skalan, men högre än jämförelsevis kostnaden för en Index Seek i 4P.
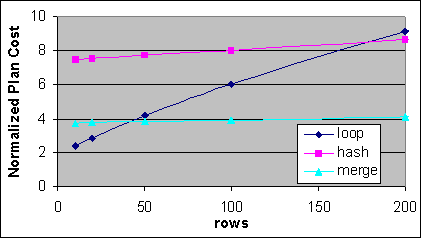
Figur 36: Normaliserad 4P kostnad för Loop, Hash och Merge JOINs (linjär skala)
Figur 37 nedan visar en Merge med sortering och en många-till-många Merge JOIN, jämfört med vanliga Loop, Hash och Merge JOINs.
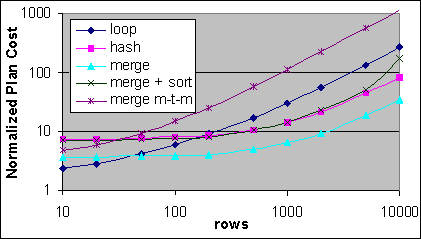
Figur 37: En Merge med sortering och en många-till-många Merge, jämfört med Loop, Hash och Merge JOINs (alla i 4P)
Merge JOIN med sortering är lite mindre dyr än Hash JOIN vid lägre antal poster, men blir lite dyrare vid högre antal poster. Kostnaden för en många-till-många Merge JOIN ligger mellan den vanliga Mergekostnaden och Hash JOIN kostnaden vid ett lågt antal poster, men blir lite högre än båda två vid ett högre antal poster.
Vid sådana tillfällen där det existerar ett sökvillkor på endast en av de båda tabellerna så skulle Hash och Merge JOINerna kräva en tabellscan mot den andra tabellen. Loop JOINen kan använda ett Index i JOIN villkoret, och därmed kunna undvika tabellscannen. Eftersom baskostnaden för en tabellscan är 6 gånger baskostnaden för ett Index Seek i 1P/2P (12 i 4P), och mycket högre än den påföljande postkostnaden, så skulle överslagspunkten för Merge mot Loop och Hash mot Loop inträffa vid ett mycket högre antal poster (500-700).
Självklart så följer Loop, Hash och Merge JOIN de beskrivningar som ges under ”Advanced Query Tuning Concepts” avsnittet av ”Optimizing Database Performance” i SQL Server Books Online. Det är hur som helst mycket mer användbart att se de faktiska siffrorna istället för att förlita sig på kvalitativa beskrivningar såsom låga, höga eller liknande.
INSERT, UPDATE och DELETE
De tre skrivoperationerna i SQL Server är INSERT, UPDATE och DELETE (IUD). Skrivoperationer kan bli ännu mer komplicerade om de involverar restriktioner, triggers eller externa nycklar. Just nu så räknas bara de grundläggande skrivoperationerna med. För var och en av dessa tre operationer så finns det olika ikoner för Heaptabeller och för tabeller med Clustrade Index, såsom visas i Figur 38, 39 och 40.
Figur 38: Exekveringsplaner för INSERT i tabell och Clustrade Index
Figur 39: Exekveringsplaner för UPDATE i tabell och Clustrade Index

Figur 40: Exekveringsplaner för DELETE i tabell och Clustrade Index
Figur 41 visar kostnadsdetaljer för tabell INSERT medan figur 42 visar kostnadsdetaljer för Clustrat Index INSERT. Figur 43 och 44 visar kostnadsdetaljer för tabell och Clsutrat Index UPDATE. Figur 43 och 44 visar kostnadsdetaljer för tabell och Clsutrat Index DELETE.
Trots att det finns vissa skillnader mellan tabell (grupp) och den Clustrade Indexoperationen i UPDATE och DELETE operationerna så är kostnaden närapå identisk. Index Seek operationen är separerad från UPDATE operationen i tabellen i den grupporganiserad tabell, men är en del av uppdateringen vid ett Clustrat Index.

Figur 41: Kostnadsdetaljer för tabell INSERT

Figur 42: Kostnadsdetaljer för Clustrat Index INSERT
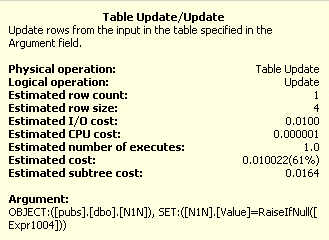
Figur 43: Kostnadsdetaljer för tabell UPDATE

Figur 44: Kostnadsdetaljer för Clustrat Index UPDATE
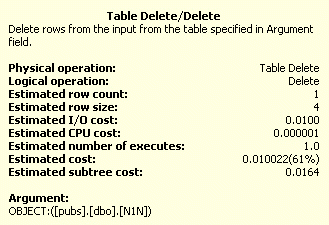
Figur 45: Kostnadsdetaljer för tabell DELETE

Figur 46: Kostnadsdetaljer för Clustrat Index DELETE
I/O kostnaden för INSERT verkar mestadels bero på antalet poster som för tillfället finns i tabellen, vilket visas i Figur 47. I/O kostnaden för INSERT är identisk för 320 poster per sida och 99 poster per sida upp till 95 poster per sida. Efteråt är skillnaden i I/O kostnaderna mindre än 0,7 %. Förändringen i I/O kostnaden kontra antalet poster kan observeras genom att stoppa SQL Server och starta om den igen. Man vet inte om den här förändringen kan observeras under andra omständigheter.
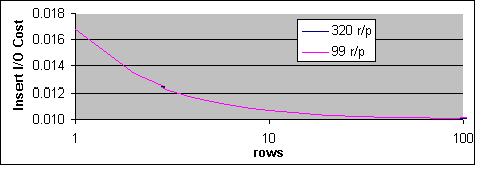
Figur 47: I/O kostnader för INSERT kontra antalet poster som finns i tabellen
I/O kostnaden för INSERT har ett mindre beroende av antalet poster per sida och ett väldigt nära beroende på huruvida en tabell har ett Clustrat Index eller inte. Figur 48 visar beroendet av poster per sida. Skillnaden på I/O kostnaden mellan tabeller som har och som inte har ett Clustrat Index är den femte decimalplaceringen.
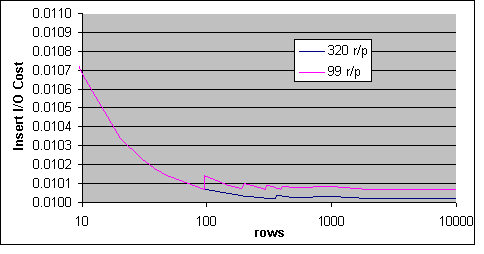
Figur 48: I/O kostnaden för INSERT
UPDATE operationen kan vara en UPDATE direkt på plats, eller en INSERT och DELETE operation, beroende på om kolumnerna som ska modifieras är av fixerad eller variabel längd och huruvida det finns tillräckligt med fri yta för de nya varibellängdfälten.
Ibland kan det finnas ett behov av att lägga in flera nya poster (som inte är utfrågade från en annan källa) till en tabell. Det konventionella valet skulle vara att skriva separata INSERT uttryck för var och en, vilket skulle göra att den höga I/O kostnaden (0,010021) skulle inträffa för varje uttryck.
INSERT N1C(ID,Value) VALUES (321,'TYI539087J')
INSERT NIC(ID,Value) VALUES (322,'TYI539087J')
Alternativet skulle vara att lägga in alla data i ett enda postset med en UNION operator, vilket visas här nedan.
INSERT N1C(ID,Value)
SELECT 321,'TYI539087J'
UNION ALL
SELECT 322,'TYI539087J'
Exekveringsplanen för INSERT uttrycket med UNION ALL klausulen visas här nedan:
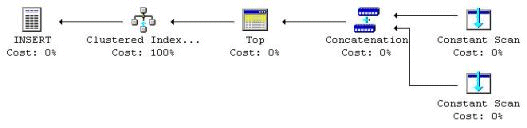
Figur 49: Att lägga in två poster med en UNION ALL operation
I ovanstående exempel så bidrar Constant Scan, Concatenation och Top operatorerna en viss extra kostnad (endast CPU), medan I/O kostnaden för INSERT endast inträffade en gång.
Constant Scan CPU kostnaden = 0.000001157 per post
Concatenation CPU kostnaden = 0.000000100 per post
Top CPU kostnaden = 0.000000100 per post
Summering av kostnaden för exekveringsplan
För tillfället så är följande observationer av kostnadsformler för exekveringsplanen värda att notera:- Kostnaden för Index Seek beror inte på Indexets omfattning
- Kostnaden för Bookmark Lookup beror inte på vilken typ av tabell det är (Clustrat eller grupp)
- I/O kostnaden för Index Seek och Bookmark Lookup är beroende av plattformerna, vilket inte de andra kostnaderna är
- Låsningslösningar (post, sida, tabell) påverkar inte kostnadsformlerna
- Kostnaden per post för extra poster i Index Seek och JOIN operationer är generellt sett mycket lägre än kostnaden för den initierande posten
Dessa punkter är relaterade till de kostnadsformlerna som Query Optimizer använder för att fastställa den bästa exekveringsplanen. Det finns inte skrivet någonstans i SQL Servers dokumentation att exekveringsplanens kostnadsformler representerar alla faktorer som kan påverka kostnaden av SQL-satsen. Det står inte heller skrivet om huruvida dessa kostnadsformler är baserade på faktiska mätningar, eller någon sorts uppskattning av kodens längd, eller inte.
Det idealiska vore om kostnadsformlerna vore så exakta som möjligt för att Query Optimizern ska kunna göra de optimala valen för den bästa exekveringsplanen. Eftersom vi fortfarande inte vet hur dessa kostnadsformler ska jämföras med de faktiska uppmätta värdena så kommer inte våra slutsatser (som egentligen skulle göras bättre enligt SQL-satsens egentliga kostnader) att tröttas ut.
Vi kan dock dra en slutsats nu. Det kan ibland finnas ett behov av att granska en databasapplikation genom testdata istället för data från produktionsmiljön. För att kunna observera den förmodade SQL-satsens exekveringsplanen för databasen så räcker det med att fylla testdatabasen med alla korrekta distributionsdata. Det är inte nödvändigt att fylla upp med alla data för hela den förväntade distributionsmiljön. Ta t ex en orderdatabas, där den typiska kunden har 10 inträden i Ordertabellen och 10 inträden per order i Order_Line-tabellen, så skulle inläggningen av ett par testkunder med den distribueringen räcka för att få den förväntade exekveringsplanen (med undantag av Bookmark Lookups och tabellscans).
0 Kommentarer