SQL Server Kvantitetsprestandaanalys #4
Förord
 Efter att ha granskat de kostnadsformler som används av SQL Server i viss detalj, så är nästa logiska steg att faktiskt mäta kostnaderna av en del grundläggande SQL-satser. Innan vi gör det så kommer vi först att gå igenom mätningsproceduren så att vi får en grund att jämföra de resultat vi får med mätningar gjorda någon annanstans. Den första punkten på listan är att välja ut ett område att mäta, vilket är CPU-cyklerna. När vi väl har etablerat ett mätområde så ska vi diskutera de förväntade behoven av processorer och plattform. Andra behov inkluderar Runtimevillkor och kvoten mellan datastorlek/minne. Den andra punkten på listan är att detaljera testprocedurerna, vilket inkluderar testtabell, datapopulation och testprogrammen. Vissa av dessa har vi redan täckt upp i tidigare artiklar i serien.
Efter att ha granskat de kostnadsformler som används av SQL Server i viss detalj, så är nästa logiska steg att faktiskt mäta kostnaderna av en del grundläggande SQL-satser. Innan vi gör det så kommer vi först att gå igenom mätningsproceduren så att vi får en grund att jämföra de resultat vi får med mätningar gjorda någon annanstans. Den första punkten på listan är att välja ut ett område att mäta, vilket är CPU-cyklerna. När vi väl har etablerat ett mätområde så ska vi diskutera de förväntade behoven av processorer och plattform. Andra behov inkluderar Runtimevillkor och kvoten mellan datastorlek/minne. Den andra punkten på listan är att detaljera testprocedurerna, vilket inkluderar testtabell, datapopulation och testprogrammen. Vissa av dessa har vi redan täckt upp i tidigare artiklar i serien.
Definitioner och övningar av mätningar
av Joe Chang
Prestanda och kostnad, mätområde
Två uppenbara val av mätområde för SQL-satskostnaden är 1) CPU-sek, och 2) CPU-cykler. Den första kan du mäta upp enkelt genom att ta CPU konsumtionen (i förhållande till 1 processor) multiplicerat med körtiden, och dividerat med antalet operationer som utfördes under mätperioden. Uppmätta värden kan tas direkt från Performance Monitor. För system med flera processorer så kan CPU konsumtionen antingen rapporteras som en procentuell del av konsumtionen från en processor eller från alla processorer, beroende på vilken Counter du använder. Ett system med 4 CPUn kan t ex rapportera att en viss process har 300 % av processortidskonsumtion, vilket är 75 % av hela systemet. Det andra mätområdet, CPU-cykler, kan beräknas genom att multiplicera CPU-sek med processorns frekvens. Ett annat alternativ är instruktionsräkningar, vilket är väldigt komplicerat så vi tänker inte ta upp den. Det finns inget inbyggt övertag av CPU-sek över CPU-cykler. Men CPU-cykler kommer hur som helst att användas eftersom det ger en bättre förståelse för skalan vid även simplare SQL operationer.Titta t ex på TPC-C standarden OnLine Transaction Processing (OLTP). Anta att ett Quad Processor 700 MHz system är kapabel till 33 000 transaktioner per minut vid en nära 100 % CPU konsumtion. Det blir 550 transaktioner i sekunden. Varje transaktion kostar 0,007273 CPU-sek på en enda 700 MHz processor. Kostnaden på 7,237 CPU-ms är inte särskilt betydelsefull. Dividera nu de konsumerade CPU-cyklerna (2 800M/sek över fyra 700 MHz processorer) med transaktionskvoten (550/sek) för en kostnad på 5,091M CPU-cykler per transaktion. Det visar tydligt att en enda TPC-C transaktion (cirka 11 SELECTs, 11 INSERTs och 11 DELETEs) inte är något att ta lätt på. Alla modifieringar som kan addera eller subtrahera tio tusen CPU-cykler till en enda transaktion kan ses som obetydlig.
Härnäst ska vi etablera ett område för validering i vårt mätområde. De faktorer som kan påverka den uppmätta SQL-satskostnaden kan placeras under följande rubriker:
1. Processor (CPU)
2. Plattform
3. Storlek på data och minne
Varje rubrik kommer att diskuteras kort. Det kan verka som om det finns så många beroenden som exkluderar möjligheten att skapa en relativt simpel modell för att kunna förutse SQL-satskostnader och systemprestanda. Men ni kommer snart att få se att vissa beroenden antingen kan vara förutsebara eller undvikliga.
Processor
Mätområdet CPU-cykler kommer att vara beroende utav flera faktorer som är relaterade till processorn. Allting som egentligen kan påverka prestanda, som antingen är oberoende av processorfrekvensen eller som inte är i exakt proportion till frekvensen, kan påverka den uppmätta kostnaden, inkluderat följande:1. Processorarkitektur (Pentium III, Pentium IV, osv)
2. Processorfrekvens
3. Processorns storlek och typ av Cache
4. Multiprocessorsystem
5. Laddande system
Den viktigaste punkten att förstå är att CPU frekvensen (MHz eller GHz) inte alls har något samband från en processorarkitektur till en annan. Det finns ingen relevans i huruvida en processorarkitektur kan göra bättre ifrån sig än någon annan vid samma frekvens, eller om den kan uppnå en högre frekvens än den andra. En given processorarkitektur kan kanske exekvera endast några få instruktioner per CPU-cykel, men som istället kanske kan uppnå en högre klockhastighet. En annan processorarkitektur kanske kan exekvera flera instruktioner per CPU-cykel, men kör vid en lägre klockhastighet. Det enda som är viktigt är den potentiella prestandan på representativa applikationer. När det gäller frekvensen så har vårt mätområde, kostnader av CPU-cykler, inget samband från den ena processorarkitekturen till den andra.
Inuti en processorarkitektur så förväntas prestandan och kostnaden av en given operation variera i takt med processorfrekvens och Cache. Man skulle kunna tänka sig att man genom att använda CPU-cyklerna i kostnadsmätområdet skulle eliminera beroendet av frekvens, men så är det inte riktigt eftersom prestandan inte ökar i exakt takt med processorfrekvensen. En 10 % ökning av processorfrekvensen skulle kunna ge en 7 % ökning av prestanda. Beroende på applikationen så skulle en stor Cache kunna prestera bättre än en mindre Cache av samma typ. Anta att vi har två processorer med identiska frekvenser, där den enas Cache är större än den andra. Processorn med den större Cachen skulle prestera bättre och därmed ha lägre kostnader för CPU-cyklerna. Cachens latens kan vara lika viktig, eller kanske viktigare än själva storleken på Cachen. De flesta processorerna idag har en tillräckligt stor Cache med låg latens och hög bandbredd, på själva processormatrisen. Stora off-matris Cache kan inte kompensera för låg latens on-matris Cache, men kan vara användbar när de används tillsammans med on-matris Cache.
Ta t ex ett system med Dual Processor 1 GHz och liten Cache, som har en uppmätt prestanda på 2 000 SQL-satser i sekunden vid en nära 100 % CPU konsumtion. Kostnaden blir då 1M CPU-cykler per SQL-sats (2 × 1,000M CPU-cykler/sek ÷ 2000 SQL-satser/sek). Ett annat system med 2x1,0 GHz processorer med små Cache kan ha en prestanda på 2 140 SQL-satser i sekunden (7 % tjänad prestanda med 10 % ökad frekvens). SQL-satskostnaden för systemet med högre frekvens skulle då bli 1,028M CPU-cykler/SQL-sats (2 × 1,100M ÷ 2140). Ett tredje system med 2x1,0 GHz processorer med större Cache har 10 % bättre prestanda (2 200 SQL-satser i sekunden). SQL-satskostnaden blir då 0,909M CPU-cykler (2 × 1,000M ÷ 2200). Man förväntar sig inte att SQL-satser som involverar stora enkelpassminnes accesser (tabellscans) ska dra fördel av en stor Cache.
En annan faktor som kan påverka kostnaden är hur många processorer som ingår i ett multiprocessorsystem (MP). I en given processorarkitektur (frekvens och Cachestorlek) så kommer även prestandan att vara beroende på antalet processorer. Med andra ord så bör ett Dual Processorsystem prestera lite sämre än det dubbla från ett system med en processor, och ett Quad Processorsystem skulle prestera lite sämre än det dubbla från Dualsystemet, osv. I exemplet ovan där systemet med 2x1,0 GHz stor Cache har en prestanda på 2 200 SQL-satser i sekunden vid en kostnad på 0,909M CPU-cykler per SQL-sats, så skulle Quad Processorsystemet prestera 1,7 gånger bättre än Dual Processorsystemet med 3 740 SQL-satser i sekunden. Kostnaden per SQL-sats skulle då bli 4 × 1000M ÷ 3740 = 1.070M CPU-cykler.
Tabell 1 nedan summerar det diskuterade exemplet i prestanda- och kostnadsvariationer med frekvens, Cachestorlek och multiprocessorsystemen.
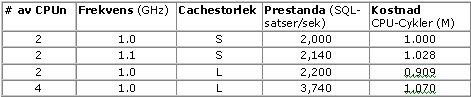
Tabell 1: Ett hypotetiskt exempel på prestanda- och kostnadsvariationer
Tabell 2 visar en jämförelse mellan prestanda och kostnad i system gällande processorarkitektur, Cachestorlek och frekvens, enligt en välkänd standard OLTP.

Tabell 2: Prestanda- och transaktionskostnader för de valda systemen
Pentium III Xeon 4x700/2M systemet har en genomsnittlig transaktionskostnad på 4,9M CPU-cykler jämfört med 5,8M på Pentium III 2x800/256K systemet. Av den större Cachen förväntas än lägre kostnad, medan det av det högre antalet processorer förväntas en kostnadshöjning. 2x2.4GHz/512K Xeon (Pentium 4 arkitekturen) systemet har dubbelt så mycket prestanda som 2P Pentium III systemet, och en kostnad av 8,3M CPU-cykler per transaktion. Pentium III och Pentium 4 processorerna har helt skilda arkitekturer, och det finns ingen relation mellan CPU-cykeln mellan de båda. Den enda viktiga punkten här är den relativa prestandan.
Det idealiska vore att göra mätningar på flera system. Men eftersom det egentligen inte är så praktiskt så kan publicerade benchmarks i runda tal ge dig en uppskattning på varje systems karaktäristiska egenskaper. Tabell 3 nedan visar SPEC CPU2000 Integer (Base) prestandan för de valda Pentium III och XEON systemen. ”Kostnaden” är beräknad genom att dividera frekvensen (i MHz) med SPEC Integer resultatet. 4P:s stora Cache Pentium III Xeon har en cirka 23 % lägre CPU-cykelkostnad än 2P:s lilla Cache Pentium III vid samma frekvens, och 2P Xeon (2,4M GHz/512K) har en 43 % högre CPU-cykelkostnad.

Tabell 3: SPEC CPU2000 Integer_Base-kostnad för de valda systemen
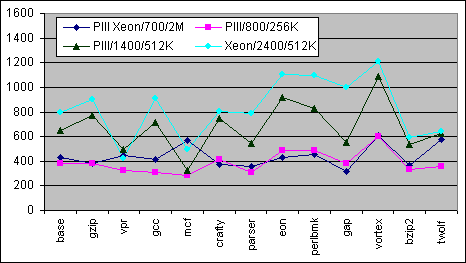
Figur 1: SPEC CPU2000 Integer_Base-kostnad för individuella program
Eftersom varje applikation svarar olika på CPU-arkitekturens funktioner (obehandlad frekvens samt Cache- och bussbandbredd) så kan det vara användbart att se på prestandan för de 12 individuella program som bygger upp SPEC CPU2000 Integern. Det är inte ovanligt för en processor att leda i vissa program och falla i andra.
Den sista punkten angår systemladdningen. För enkelhetens skull så kvoteras de flesta prestandarapporteringar vid toppar under systemladdningen, där CPU konsumtionen är nära 100 %, eller så högt som den går att få. I praktiken så körs de flesta system väl under en 100 % konsumtion. Anta att den uppmätta prestandan är 300 SQL-satser i sekunden vid en 10 % CPU konsumtion, det innebär inte att topprestandan kan gå ända upp till 3 000 SQL-satser vid en CPU konsumtion på 100 %. Generellt sett, då systemladdningen ökar, så kommer det att bli en ökad rivalitet för resurser, inte lägre. Därför kan det förväntas att kostnaden per operation kommer att öka med systemladdningen. Det här är förmodligen mer karaktäristiskt för Servrar med mellanlagers-applikationer. SQL Server är känt för att visa en väldigt god linjäritet mellan prestanda och CPU konsumtion. Operativsystemet har också vissa bakgrundsprocesser. Vid en högre systemladdning så bör bakgrundsprocesserna ta en mindre del av den totala arbetslasten. I de flesta fall så mäts kostnad och prestanda med en CPU laddning som har drivits så långt som möjligt, vanligtvis 90 % eller mer. I vissa fall kan det också vara värt väntan att observera prestanda över flera systemladdningar.
Plattform
Den underliggande plattformen, mer specifikt chip-setet, kan påverka prestandan oavsett vilken processor det är. De primära funktioner som är implementerade i chip-setet som påverkar prestandan är den potentiella minnesbandbredden och latensen. Ett chip-set länkar samman tre eller fyra olika typer av bussar; processorn (processorerna), minnet, I/O samt möjligtvis en separat grafisk buss. I låga kostnadssystem så kan systembussen som länkar CPUn vanligtvis ha samma bandbredd som bussen som länkar minnet. Ibland kan det bli en missmatchning då systembussen är kapabel till mer bandbredd än vad minnesbussen är. Pentium IV processorn var designad för Rambus minne (RDRAM) med två kanaler vid 3,2GB/sek. På grund av komponentkostnaderna så blev ofta Pentium IV systemen ofta matchade med en enda 100MHz SDRAM minneskanal på 800MB/sek eller en 200MHz DDR kanal på 1,6GB/sek. Mer kapabla Serversystem kan ha ett chip-set som länkar minnesbussar som har två eller fyra gånger bandbredden på systembussen.
Det kan hända att många system och chip-set kan referera till toppminnets systembandbredd. En 64-bits minnesbuss som kör vid 133MHz har en bandbredd på 1,06GB/sek. Det kan verka som om ett minnessystem med högre bandbredd än processorbussens bandbredd än överflödig och oanvändbar, och att ett minnessystem med lägre bandbredd är en potentiell krympling. Faktum är att detta inte är helt sant, eftersom vissa applikationer inte alltid har någon begränsning på minnesbandbredd.
Toppbandbredden kan endast uppnås om minnesaccessen är under hög påfrestning, där minnets krav tas om hand innan den sista (eller flera andra) är avslutade. Det här uppstår vanligtvis vid stora seriella blockoperationer. Många applikationer (inklusive SQL Server) har en betydlig portion av små, eller icke-seriella, minnesaccesser. Ett faktum som sällan nämns är det gällande minnets latens. SDRAM kan köras vid en 133MHz bussfrekvens, DDR kan köras vid 266MHz (och högre) och Rambus ska kunna köras över 800 MHz. Den här bussfrekvensen representerar tidsintervallet mellan dataöverföringar. Vid 100MHz så är tidsintervallet 10ns, och vid 200MHz så är tidsintervallet 5ns. Minnets latens refererar till tidsintervallet mellan att minnet begär data tills det har fått alla data. Minnets latens från det att den begär data tills att överföringen är avslutad är vanligtvis mer än 100ns. För en 1GHz processor med en 1ns klocka så är minneslatensen mer än 100 CPU-cykler.
De skadliga följderna av en lång minneslatens kan till en viss utsträckning gömmas bakom ett låg-latensigt Cacheminne, samt en ”för-hämtande” och ”piplinjig” minnesaccess. För-hämtning refererar till att handskas med minnets efterfrågningar innan det egentligen behövs. Piplinjig minnesaccess innebär att nästa efterfrågning från minnet tas om hand innan den aktuella accessen har avslutats. Vissa ärftliga minnesaccesser kan inte Cachas, och kan inte heller blir effektivt ”för-hämtade” eller ”piplinjade”. Det här kan uppstå om den aktuella minnesaccessen innehåller information som krävs för att kunna ta hand om nästa minnesaccess.
I vissa aspekter av applikationens beteenden så förväntas konsumtionen av minnesbussen vara låg. Minnesprestandan kan bäst karaktäriseras genom dess förmåga att utföra små icke-seriella minnesaccesser. I det här fallet så kan flertalet minneskanaler ha en bättre prestanda än en enda kanal, trots att man inte använder den fulla bandbredden av alla kombinerade minneskanaler.
I/O kapaciteten kan också vara viktig. Många Serverplattformer stödjer nu 64-bits PCI-bussar, inklusive operationer på 66MHz eller snabbare. De testsystem som har använts har diskssystemet kopplat till en 64-bit/33MHz PCI-buss samt nätverksadaptern Full-Duplex Fast Ethernet kopplat till en 32-bit/33MHz PCI-buss. I de flesta tester så anser man inte att varken disken eller nätverket är någon flaskhals. Det är möjligt att vissa av testerna skulle ha kunnat dra fördel av en GigaByte Ethernet adapter.
Storlek på data och minne
En annan faktor som kan påverka prestanda är storleken på databasen i relation till mängden systemminne som är tillgängligt för Buffring. De flesta databasprodukter, inklusive SQL Server, var i grund och botten designade till att arbeta under diskcaching-förhållanden. Alla data lagras permanent på hårddiskarna, medan data som ofta accessas buffras i minnet. Det här förutsätter generellt att datastorleken är mycket större än mängden tillgängligt minne, vilket reflekterar de tidigare höga kostnaderna för minnet.Det kan verka som om prestandan beror väldigt mycket på datastorleken i relation till mängden tillgängligt minne för Buffring, men det är inte riktigt sant under alla omständigheter. Latensen för en fysisk diskaccess är väldigt lång. En väldigt snabb hårddisk skulle kunna kvarhålla blandade I/O efterfrågningar på 5ms per access. I CPU-cykler för en 1GHz processor så innebär det här 5M CPU-cykler, eller en evighet i CPU tid.
Medan latensen för fysiska diskaccesser är väldigt lång (relativt till CPU kärnan) så innebär inte det att CPU kostnaden för en fysisk disk I/O operation också är hög. När väl den fysiska disk I/O efterfrågningen är omhändertagen så kan operativsystemet byta till en annan uppgift. Så länge som Buffer Hit kvoten är någorlunda hög så kan den fysiska disk I/O kostnaden vara låg (relativt till andra aktiviteter). Det här är bevis på att majoriteten av CPU kostnaden inträffar i den logiska I/O operationen, efter att alla data har förflyttats från hårddisken till minnet.
Mer minne kan reducera efterfrågningarna från disk I/O, men det behöver inte betyda att prestandan höjs till en acceptabel nivå. Så länge som disksystemet kan hantera I/O, och så länge som det finns oberoende arbeten att ta hand om, så kan det vara så att prestandan inte påverkas nämnvärt. Ett antal källor föreslår att SQL Server kan arbeta utmärkt med ett minne som är lika stor som ungefär en tiondel av databasens storlek. Standarder som TPC-C påstår att data med en storlek på 150GB kan klara sig på 3GB minne (tillgängligt för SQL Server) utan några större prestandadegraderingar.
Nu när priserna för minnen är så pass låga så är frågorna angående hur mycket minne man ska konfigurera in för att få bättre prestanda, diskuterbara. Även om extra minne – större än en viss procentuell del av datastorleken – ger en mycket liten ökning av prestandan så kan det fortfarande resultera i färre efterfrågningar från disk I/O. Så länge som kostnaden av extra minne är lägre än kostnaden av I/O kapaciteten från ett disksystem utan extra minne, så skulle det i så fall vara fördelsaktigt. I de flesta praktiska fall så skulle en databasapplikation som hanterar transaktionsprocesser vara konfigurerad med tillräckligt minne för att få plats i hela data-setet, vilket i sådana fall skulle leda till att Random I/O prestandan av disksystemet inte skulle vara något problem. Det är endast transaktionsloggen som behöver tillräckligt med seriell disk I/O kapacitet.
För att hålla systemkonfigurationen enkel och irrelevant så kommer de flesta testerna att använda data som får plats i minnet, och man kommer dessutom att köra en gång först för uppvärmning, för att ladda upp alla data i minnet innan man börjar med mätningarna.
Databasens testtabeller och lagrade procedurer
De två typer av testtabeller som används här är samma två tabeller som vi använde då vi granskade exekveringsplanens kostnadsformler tidigare i artikelserien. N1x tabellerna har två kolumner som får plats med cirka 320 poster per sida vid en fyllfaktor på 90 %. Mxx tabellerna har flertalet kolumner av fixerad datatyplängd, som får plats med 99 poster per sida vid en fyllfaktor på 90 %. Variationer av den här tabellstrukturen har ett Clustrat Index, icke-Clustrade Index på grupper (inga Clustrade Index), eller inga Index alls.Alla SQL-satser som ska testas bör tas om hand genom en lagrad procedur, istället för rakt på. Det här är Microsofts rekommenderade tillvägagångssätt vid prestandakritiska applikationer, och det är också fokusen i den här artikelserien. Nedan visas ett exempel på en lagrad procedur. Den lagrade proceduren har fem parametrar av olika typer som alla är definierade som Output-parametrar, och där inte alla egentligen används. Syftet med det är att låta alla tester få köra med identiska parameterlistor, oavsett om huruvida varje parameter egentligen krävs för den specifika SQL-satsen eller inte. Proceduren har också två skalfunktioner, såsom random siffergeneratorn och moduler. Det här tynger återigen alla testfall med samma mängd av arbetslast.
CREATE PROC p_get_N1C_01(@ID int = 1 OUTPUT, @Count int = 0 OUTPUT,
@Value VARCHAR(250) = '' OUTPUT, @RANDINT INT = 0
OUTPUT, @ERRMSG VARCHAR(255) = '' OUTPUT )
AS
BEGIN
SET NOCOUNT ON
DECLARE @Value1 CHAR(10)
IF @RANDINT > 0 SET @ID = 320*@RANDINT*RAND() + 1
IF @ID > 320 SET @ID = @ID % 320 + 1
SELECT @Value1 = Value FROM N1C_01 WHERE ID = @ID
SELECT @Value = @Value1
RETURN 0
ERROR:
RETURN 1
END
Lista 1: En lagrad procedur med fem Output-parametrar och skalfunktioner
Faktum är att för några av de enklare SQL-satserna så kan kostnaden av att kalla på den lagrade proceduren vara högre än kostnaden för själva SQL-satsen. För att lättare kunna lösa problemet med kostnaden för bara SQL-satserna så kommer några av testerna att ha två eller flera SQL-satser i en enda lagrad procedur. Det kan också vara användbart att mäta själva kostnaden för proceduren, utan några SQL-satser som involverar en tabelloperation.
Testprogram för generatorladdning
Efter att ha fastställt det som krävs för att mäta en SQL-satskostnad så ska vi nu ha en kort diskussion om testprogrammen för generatorladdning. Det finns ett antal tredje-partens verktyg tillgängliga, vilka kan generera väldigt sofistikerade script – script som kan simulera flera villkor som kan uppstå i vanliga fall. Hur som helst så är vår strategi att börja med att testa individuella SQL-satser. Ett senare mål skulle kunna vara att försöka avgöra om prestandan eller kostnaden av de individuella SQL-satserna kan kombineras samman, för att kunna förutse prestandan av en kombinerad blandning av SQL-satser.I det här fallet så räcker det med en simpel loop runt en enda SQL-sats. Visual Basic (upp till version 6.0) är ett väldigt populärt utvecklingsverktyg, men det stödjer inte multitrådning (multi-threading). (Microsoft SQL Server 2000 Resource Kit innehåller ett databashammerprogram med VB källkod). Ett Visual C/C++ program kan hantera multitrådning, men det är lite mer komplicerat. De nya VB.NET och C#-språken är både enkla att programmera och de stödjer multitrådning.
Dim objConn As New ADODB.Connection
Dim objCmd1 As New ADODB.Command
objConn.Open "Driver=SQL Server; Server=server;
Database=pubs;UID=sa;PWD="
Set objCmd1.ActiveConnection = objConn
objCmd1.CommandText = "dbo.p_get_N1C_01"
objCmd1.CommandType = adCmdStoredProc
objCmd1.Parameters.Append objCmd1.CreateParameter( "ReturnCode",_
adInteger, adParamReturnValue)
objCmd1.Parameters.Append objCmd1.CreateParameter( _
"ID", adInteger, adParamInputOutput, 4, 1)
etc,
For nLoop = 1 To 10000
objCmd1.Execute, lngRecordsAffected, adExecuteNoRecords
Next nLoop
Set objCmd1 = Nothing
objConn.Close
Set objConn = Nothing
Lista 2: Ett utdrag från ett VB program för generatorladdning
Felet med ett VB generatorladdningsprogram är det att ett enkeltrådat program inte kan tynga ner databasservern. I ett Pentium III 733MHz system med två processorer så kanske lasten på databasen, för både generatorladdningen och databasservern, bara blir cirka 600 SQL-satser i sekunden vid ~7 % CPU för enklare SQL-satser. De huvudsakliga anledningarna är 1) att nätverkets broadcastlatens är hög relaterat till den faktiska tid det tar för databasservern att exekvera en SQL-sats, och 2) att enklare SQL-satser kan köras i en enda process, och inte dra fördel av alla tillgängliga processorer. Ett 2P Pentium III 733MHz system som kör 10-12 generatorladdningsprocesser, kan köra cirka 4 000 SQL-satser i sekunden. Ett flertrådat generatorladdningsprogram som är skrivet i antingen C/C++ (ODBC) eller i C# (ADO) kan köra över 7 000 SQL-satser i sekunden på samma system. En ensam Full-Duplex Ethernet adapter kan köra över 13 000 anrop i sekunden med den lagrade proceduren som vi beskrev tidigare. Om vi tänker praktiskt så skulle C# vara verktyget att föredra för vårt generatorladdningsprogram, men VB/ADO och C/ODBC kan också användas ibland. Nedan visas ett utdrag från en C/ODBC kod.
SQLAllocHandle(SQL_HANDLE_STMT, hdbc, &hstmt1);
SQLBindParameter(hstmt1, 1, SQL_PARAM_INPUT, SQL_C_ULONG,
SQL_INTEGER, 5, 0, &ID, 0, &cbID);
…
for (nLoop=0; nLoop < 10000; nLoop++) {
SQLExecDirect(hstmt1, (SQLTCHAR*) szSQLSelect, SQL_NTS);
}
Kostnaden I CPU-cykler för en SQL-sats kan beräknas enligt formeln nedan.
CPU-cykler = (# av CPUn) × (Frekvens) x (Runtime) × (CPU Konsumtion)
÷(Iterationer)}
Posträkningar kontra Indexdjup
En av de frågor som vi måste granska är den om kostnaden för en Index Seek kontra Indexdjupet. Indexdjupet är antalet nivåer i Indexet. Det kan vara användbart att se över ett kort exempel som illustrerar Indexdjupet kontra posträkningen. I vårt exempel innefattar det Clustrade Indexets övre nivåsidor och det icke-Clustrade Indexets nivåsidor 500 poster, och det Clustrade Indexet lövnivåsidor innefattar 100 poster. Postdensiteten på varje sida beror på storleken av Indexet samt fyllfaktorn. Tabell 4 nedan summerar det maximala antalet poster för Indexdjupet.
Tabell 4: Max poster för Indexdjup 2 till 4, för 500 poster per Indexsida och 100 poster för det Clustrade Indexets lövnivå
Man kan tydligt se att för ett litet Index (i antal bytes) så kommer de flesta tabeller att ha ett Indexdjup på 1-3. Endast några få väldigt stora tabeller kommer högst troligen att ha ett Indexdjup på 4 eller högre.
0 Kommentarer