SQL Server Kvantitetsprestandaanalys #5
Förord
 De huvudsakliga SQL Server plattformerna som används är Pentium III 733MHz systemet med två processorer (2x733/256K), ett liknande system vid 600MHz (2x600/256K), Pentium III Xeon 700MHz systemet med fyra processorer (4x700/2M) samt ett Dual Xeon 2.0GHz system (2x2.0G/512K). Några testkörningar skedde även på ett Pentium III Xeon 500MHz system med två processorer (2x500/2M). Alla Dual Processor Pentium III plattformer använde ServerWorks LE chip-setet (en minneskanal, 133MHz systembuss). Fyra-processorsystemet använde ServerWorks HE chip-setet (dubbla minneskanaler, 100MHz systembuss). Dual Xeon systemet använde ServerWorks GC-LE chip-setet. Den nyaste Pentium III med 512K on-die Cacheprocessor har ännu inte utvärderats.
De huvudsakliga SQL Server plattformerna som används är Pentium III 733MHz systemet med två processorer (2x733/256K), ett liknande system vid 600MHz (2x600/256K), Pentium III Xeon 700MHz systemet med fyra processorer (4x700/2M) samt ett Dual Xeon 2.0GHz system (2x2.0G/512K). Några testkörningar skedde även på ett Pentium III Xeon 500MHz system med två processorer (2x500/2M). Alla Dual Processor Pentium III plattformer använde ServerWorks LE chip-setet (en minneskanal, 133MHz systembuss). Fyra-processorsystemet använde ServerWorks HE chip-setet (dubbla minneskanaler, 100MHz systembuss). Dual Xeon systemet använde ServerWorks GC-LE chip-setet. Den nyaste Pentium III med 512K on-die Cacheprocessor har ännu inte utvärderats.
Innehåll
»»
»
»
»
»
»
»
»
»
»
»
»
Kostnader för SELECT-satser
av Joe Chang
Vi ska testa SQL-satser genom många av de grundläggande SQL-operationerna. En enda mätning kan kalkylera fram kostnaden av hela SQL-satsen, tillsammans med belastningen från anropen. En komponentoperation kan inte granska sig själv. Man kan ibland mäta två separata SQL-satser, där de enda skillnaderna mellan dessa två är en särskild komponentoperation, för att därigenom härleda fram komponentkostnaden. Vi kommer att göra ett försök att fastställa baskostnaden för de specifika operationer som involverar en enda post, samt kostnaden av de extra poster vilka är relaterade till de formler som fastställdes för SQL Serverns interna SQL-satskostnader. Andra behov ska också granskas, inklusive kostnaden av en Index Seek kontra Indexdjupet samt vilken påverkan Lock Hints har, men dessa kommer inte att räknas med i plankostnadsformlerna. Vi ska också ta reda på antalet logiska läsningar (I/O operationer) för vissa SQL-satser genom Outputen från STATISTICS IO.
Tester för SQL-sats till tabell med en sida
De första testerna tittar på en enkel SQL-sats som returnerar en enda post från en tabell med en sida, vilket visas nedan.SELECT Value FROM N1x WHERE ID = @ID
N1x tabellen, som vi definierade i en tidigare artikel, är fylld med 320 poster som resulterar i en fyllfaktor på cirka 90 % på en enda 8kb sida. Det finns två uppenbara Indexalternativ för SQL-satsen ovan, och dessa är 1) ett Clustrat Index på ID kolumnen, och 2) ett icke-Clustrat Index på ID kolumnen. Figur 1 visar tre exekveringsplaner den här SQL-satsen.
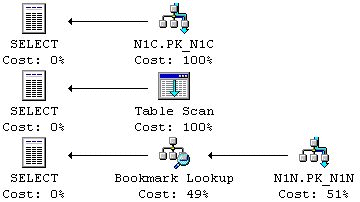
Figur 1: Exekveringsplaner för testsatsen
Exekveringsplanen för det Clustrade Indexalternativet har bara Index Seek-operationen. Det icke-Clustrade Indexalternativet kräver både Index Seek- och Bookmark Lookup-operationer. Den tredje exekveringsplanen är en tabellscan, vilket kan inträffa om det inte finns några lämpliga Index att använda.
Mystiskt nog så kräver den Clustrade Indexsökningen 2 logiska I/O operationer, trots att alla poster får plats på en enda lövnivåsida. En möjlig förklaring till det kan vara att ett Clustrat Index alltid har en rotnivåsida separat från lövnivåsidan. SQL-satsen på tabellen med ett icke-Clustrat Index visar 2 I/O operationer. Bookmark Lookupen tar 1 I/O operation så Indexsökningen kan bara ta 1 I/O operation själv. Det icke-Clustrade Indexet verkar inte kräva några separata rotnivå- och lövnivåsidor. Det leder oss till ett tredje Indexalternativ för en mindre tabell som bara tar upp en enda sida, ett täckande Index på ID kolumnen följt av Value-kolumnen. Outputen från STATISTICS IO bekräftar att det verkligen bara krävs en enda I/O operation för den SQL-sats som körs mot ensidestabellen med det täckande Indexet. Tabellscannen kräver också 1 logisk I/O operation. Tabell 1 summerar antalet I/O (för att se om I/On inträffades på ett Index eller i tabellen) för de fyra exekveringsplaner som diskuterades för SQL-satsen mot en ensidestabell.
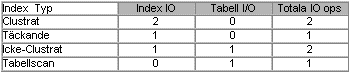
Tabell 1: Logiska I/O-räkningar för singelpost SELECTs från en ensidestabell
Figur 2 här nedan visar SQL-satsens prestanda för SELECTen mot N1x tabellerna på Pentium III 2x733/256K Servern, för de två Indextyperna och tabellscannen för 1 till 10 SELECT-SQL-satser per lagrad procedur. Figur 3 visar samma test fast på ett 4x700/2M Pentium III Xeon system.
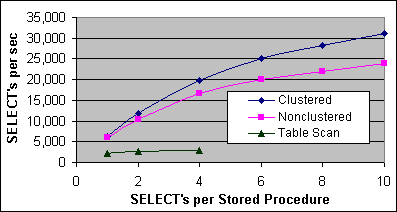
Figur 2: SQL-satsens prestanda, en eller flera SQL-satser per procedur (2x733)
Det finns en belastningskostnad för varje externt proceduranrop (RPC – ”Remote Procedure Call”). Kostnaden inträffar för både lagrade procedurer och SQL-uttryck. Belastningen inkluderar både operativsystemets kostnad för nätverkstransmissionen samt SQL Serverns kostnad för att ta hand om en förfrågan. För en lagrad procedur med en SQL-sats (Clustrat Index) så är 2x733:s prestanda ~6 350 operationer i sekunden. För lagrade procedurer med två SQL-satser så är dess prestanda ~5 900 lagrade procedursanrop i sekunden, samt 11 800 SELECTs i sekunden. Man kan tydligt se att belastningskostnaden är hög relativt till kostnaden för själva Index Seek operationen.
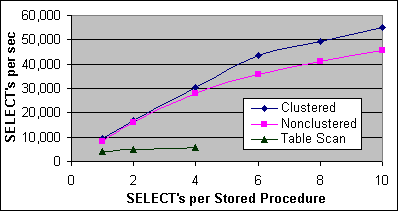
Figur 3: SQL-satsens prestanda, en eller flera SQL-satser per procedur (4x700/2M)
Figur 4 visar CPU-cykelkostnaderna för de lagrade procedurerna från 2x733/256K testerna. Kostnaden beräknas genom att multiplicera tillgängliga CPU-cykler (2 x 733M / sek) gånger körtid gånger CPU konsumtion, dividerat med antalet SQL-satser som utförs.
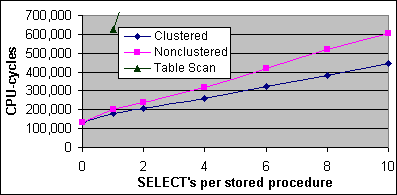
Figur 4: Kostnad per lagrad procedur (2x733/256K)
Den uppmätta kostnaden av ett lagrat proceduranrop utan SELECT-satser (där proceduren tar fem parametrar, kalkylerar två skalfunktioner och stänger ner) är 140 000 CPU-cykler på testsystemet. Den här kostnaden kan komma att bero på ett antal villkor. Den uppmätta kostnaden på olika system har visat sig vara allt från 130K-160K CPU-cykler. Den här kostnaden kan bero på antalet och typ av parametrar i den lagrade proceduren, på skaloperationerna samt på hur en SQL-satserna hanteras – men kostnaderna av dessa variationer har ännu inte utforskats. Trenden verkar dock indikera på att kostnaden för den lagrade proceduren verkligen är kostnaden för den belastning som sker utanför själva SQL-satsen. I vissa fall så använder SQL Serverns ODBC drives sp_executesql för att implementera SQLExecDirect. Med det C-baserade ODBC generatorladdningsprogrammet så verkar kostnaden för belastningen vid en lagrad procedur vara ungefär 210 000 CPU-cykler, då den hanteras med sp_executesql. Kostnaden av den lagrade proceduren med 5 parametrar och 2 skalfunktioner kommer att refereras som basbelastningen i den här artikeln.
exec sp_executesql
N'exec p_get_N1C_01 @P1,@P2,@P3,@P4,@P5',
N'@P1 int,@P2 int,@P3 varchar(250),@P4 int,@P5 varchar(255)',
1, 0, '', 0, ''
Not: Lagrade procedurers Case-känslighet vid namn
Någonting du bör var noga med är att matcha stora och små bokstäver vid de lagrade procedurnamnen. Om det kompletta namnet på proceduren faktiskt är dbo.p_get_N1C och dbo.p_get_n1c istället skrivs in så kommer SQL Profiler att visa 7 läsningar för varje procedur istället för 2, vilket ger en uppmätt belastningskostnad på cirka 240 000 CPU-cykler istället för cirka 140 000. Det är också möjligt att det kan uppstå en extra kostnad om inte användaren är angiven och då procedurägaren är dbo, men detta har ännu inte testats.
Figur 5 visar kostnaden per SQL-sats för 2x733/256K systemet, och Figur 6 visar kostnaden per SQL-sats för 4x700/2M systemet. Kostnaden har beräknats genom att subtrahera basbelastningskostnaden (140 000 för VB/ADO generatorladdningsprogrammet och 210 000 för C/ODBC programmet) och dividera det med antalet SQL-satser per lagrad procedur.
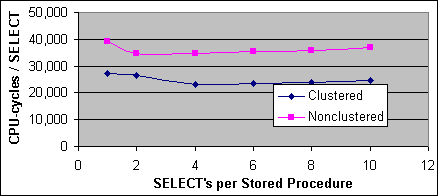
Figur 5: Kostnad per SELECT-sats med en enda post (2xPIII-733/256K)
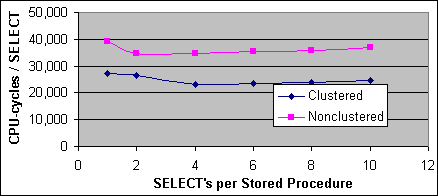
Figur 6: Kostnad per SELECT-sats med en enda post (4xPIII-700/2M)
Den lagrade proceduren med endast en SELECT-sats har en högre kostnad jämfört med procedurer med många SQL-satser, på cirka 20 000 CPU-cykler för både de Clustrade och de icke-Clustrade Indexplanerna på 2x733/256K systemet. Det här kan bero på mätningsfel eftersom den tomma lagrade proceduren är mycket dyrare än kostnaden av en enda SELECT, men mönstret uppstår ändå i flera andra mätningar, speciellt på system med mindre Cache. Det är möjligt att det finns en annan engångskostnadskomponent som inte uppstår i en lagrad procedur utan tabelloperationer. Den här belastningskostnaden är dock mindre – eller försumbar– på system med större Cache, men den egentliga orsaken har ännu inte verifierats. Där det går så refereras den här kostnaden som SQL-satsens uppstartningskostnad. Uppstartningskostnaden varierar med typen av operation och plattform, där plattformens påverkan högst troligt är relaterad till Cachestorleken. Kostnadsformeln för flera SQL-satser per lagrad procedur ser ut så här:
Total kostnad = Basbelastning + SQL-satsens uppstartningskostnad + Kostnad per SQL-sats × Antal SQL-satser
Det här verkar indikera på att kostnaden för en SELECT-sats med en enda post på 2x733/256K systemet är 32 000 CPU-cykler för en Clustrad Indexsökning samt 48 000 CPU-cykler för en icke-Clustrad Indexsökning och Bookmark Lookup. På 4x700/2M systemet så är de två plankostnaderna 24 000 respektive 36 000 CPU-cykler. Den uppmätta kostnaden för den täckande Indexsökningen är ungefär samma som för den Clustrade Indexsökningen, trots att den täckande Indexplanen kräver 1 I/O operation och den Clustrade Indexplanen kräver 2 I/O operationer.
Kostnaden för tabellscannen med 320 poster och 1 sida är (efter att man har subtraherat bort basbelastningen) 480 000 CPU-cykler på båda systemen, trots att det bara finns 1 I/O operation involverad.
Kostnaden för Index Seek och Bookmark Lookup kontra Indexdjupet
Nästa uppgift är att avgöra kostnaden för enkelpost Index Seek och Bookmark Lookup operationer över olika Indextyp- och djupvillkor. Någonting man kan förvänta sig är att kostnaden av en icke-Clustrad Indexsökning följt av en Bookmark Lookup är dyrare om den underliggande tabellen har ett Clustrat Index, än om den vore en grupp. En annan sak att vänta sig är att kostnaden av en Indexsökning beror på antalet Indexnivåer, vilket påverkar själva Indexsökningen samt Bookmark Lookupen på ett Clustrat Index. Exekveringsplanens kostnadsformler visar inte på något av beroenden. M tabellerna har fyllts för att uppnå ett specifikt Indexdjup. För ett fyra bytes Integerindex så får det plats lite drygt 600 poster på en Indexrotsida vid en fyllfaktor på 90 %. Det Clustrade Indexets lövnivå innehåller 99 poster. Ett Indexdjup på 2 tillåter cirka 61 000 poster för ett Clustrat Index samt ordningen av 300 000 poster för ett icke-Clustrat Index vid standardfyllfaktorn. I testet så har M tabellerna fyllts med 50 000 poster för ett Indexdjup på två för både Clustrade och icke-Clustrade Index, med 200 000 poster för ett Clustrat Indexdjup på 3 och ett icke-Clustrat Indexdjup på 2, samt med 500 000 poster för ett Indexdjup på 3 för både typerna av Index.
Tabell 2 summerar den logiska I/O räkningen för Clustrat Index (Cl), icke-Clustrade Index på en grupp (NH), samt för icke-Clustrade Index på en tabell med ett Clustrat Index (NC). Det maximala antalet poster som ett Indexdjup på 3 kan ha är självklart är 30M för det Clustrade Indexet och 200M för det icke-Clustrade Indexet. Det är möjligt att en Indexsökning på ett djup 3 Index som är fullt är dyrare än en sökning där antalet poster nätt och jämnt kräver 3 Indexnivåer. Antalet I/On har listats separat för Index Seek och Bookmark Lookup. Antalet I/On för en Bookmark Lookup är alltid 1 om tabellen är en grupp. För icke-Clustrade Index på ett Clustrat Index så är antalet I/On för en Bookmark Lookup lika många som för den Clustrade Indexsökningen. Grafkoderna används i Figurerna 7 till 9.
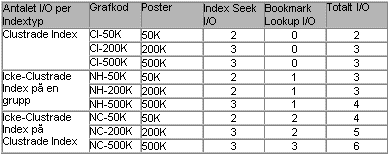
Tabell 2: Antalet logiska I/O per Indextyp, tabellorganisation och antalet poster
Figur 7 visar prestanda för SQL-satser i antalet SELECTs per sekund, och Figur 8 visar den uppmätta kostnaden per SELECT-sats på en 2x733/256K Server. Som vi förväntade oss så kan man tydligt se att Bookmark Lookupen är dyrare för en tabell med ett Clustrat Index än för en grupptabell. Kostnaden för Index Seek operationen visar också beroendet av antalet poster (och förmodligen också Indexdjupet).
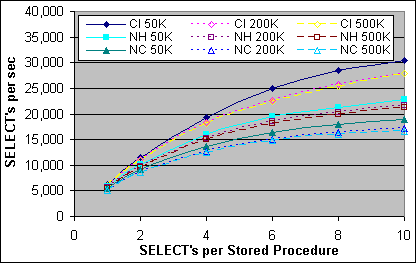
Figur 7: Prestanda för en enkelpostindexerad SELECT-sats (2x733/256K)
Figur 8: Lagrad procedurkostnad för en enkelpost SELECT-sats (2x733/256K)
Figur 9 visar kostnaden per SQL-sats, beräknad genom att subtrahera basbelastningen (140K) och sen dividera med antalet SQL-satser. SQL-satsprestandan och kostnaden på tabellen med ett Clustrat Index vid 50K poster (Cl 50K) är närapå identisk med kostnaden för N1C tabellen med 320 poster. Båda två kräver 2 I/O operationer för en Clustrad Indexsökning. Kostnaden för SQL-satsen mot ett icke-Clustrat Index på grupptabellen vid 50K poster (NH 50K) är lite dyrare än kostnaden för N1N tabellen (50K respektive 48K CPU-cykler). Skillnaden är att det krävs 2 I/O operationer för den icke-Clustrade Indexsökningen vid 50K poster, och endast 1 I/O operation för N1N tabellen. Figur 10 visar kostnaden per SQL-sats för ett Dual Xeon system.
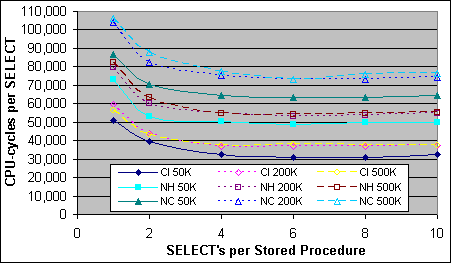
Figur 9: Kostnaden för en enkelpost SELECT-sats (2xPIII-733/256K)
Den uppmätta kostnadsformeln för enkelpost SELECT-satserna kan delas upp i tre olika delar. För det första så är det basbelastningskostnaden. För det andra så skapar de små Cachesystemen (256K) en uppstartningskostnad på mellan 20-30K CPU-cykler utöver basbelastningskostnaden. 4x700/2M systemet har ingen tydlig extra kostnad utöver basbelastningen. Och slutligen så kommer själva SQL-satskostnaden. Den första och andra delen uppstår en gång per lagrad procedur, och SQL-satskostnaden (som visas i Tabell 3) uppstår en gång per SQL-sats.
Kostnader som uppstår en gång per lagrad procedur:
Basbelastning
Pentium III/256K normal 140,000 CPU-cykler
Pentium III Xeon/2M normal 140,000 CPU-cykler
Xeon 2.0GHz/512K normal 270,000 CPU-cykler
PIII (both) sp_executesql 210,000 CPU-cykler
Uppstartningskostnad för SQL-sats
Pentium III/256K 20,000-30,000 CPU-cykler
PIII Xeon 0?
Xeon 2.0GHz/512K 30,000
Figur 10: Kostnaden för en enkelpost SELECT-sats (2xXeon-2.0G/512K)
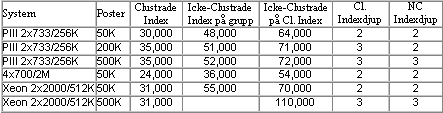
Tabell 3: Enkelpostkostnader för Index Seek och Bookmark Lookups
Ökningen från 50K till 200K i fallet med det Clustrade Indexet var att förvänta eftersom Indexdjupet ökade från 2 till 3. Att det inte ger någon förändring då posterna ökar från 200K till 500K poster leder oss till att tro att den Clustrade Indexsökningen inte är beroende av Indexets fyllfaktor, utan endast på djupet. Det här stöds också av det faktum att den N1C (320 poster) Clustrade Indexsökningen kostar lika mycket som M2C (50K poster). För det icke-Clustrade Indexet på en grupp så ökar kostnaden med cirka 3K CPU-cykler från 50K till 200K poster, där Indexdjupet hålls kvar på 2. Indexdjupet ökar till 3 vid 500K poster, men kostnaden ökar bara med 1K. Men det kan bero på något fel med mätningen. För det icke-Clustrade Indexet på det Clustrade Indexet så förväntas den uppmätta kostnaden att öka från både 50K till 200K och sen återigen till 500K. Från 50K till 200K för den Clustrade Indexvägen i Bookmark Lookupen kräver en extra I/O. Det krävs ytterligare en I/O från 200K till 500K poster för den icke-Clustrade Indexsökningen. De uppmätta kostnaderna visar då en större ökning från 50K till 200K poster, och en mindre ökning från 200K till 500K.
Man kan tydligt se att kostnaden för Index Seek operationen beror på antalet poster, men beroendet är inte baserat på endast Indexdjupet. Indexets fyllfaktor förväntas påverka kostnaden av Index Seek operationen, men denna relation är inte tydlig. Hur som helst så förväntas beroendet mellan kostnaden av Indexsökningen och antalet poster vara lågt om Indexet är relativt kompakt. Om det får plats 400 poster på en Indexsida så kan ett icke-Clustrat Index med djupet 3 hålla (400)3 eller 64 miljoner poster. Det är också tydligt att Bookmark Lookup operationen för en tabell som är byggt på ett Clustrat Index är dyrare än en grupporganiserad tabell. Om SQL-satser mot en tabell körs med olika sökargument utan att föredra något speciellt så kan det nog vara bäst att inte skapa ett Clustrat Index. En mer exakt metod för att kunna göra det här valet kan göras efter att ha granskat en tabellscan och multipost SELECT-satser.
Xeon 2.0GHz systemet förväntas ha dubbla prestandan av ett Pentium III 733MHz system. Eftersom frekvensen är ungefär tre gånger så hög så kan man också räkna med att kostnaden av CPU-cyklerna är 1,5X högre än för Pentium III 733MHz systemet. När det händer så blir även basbelastningskostnaden dubbelt så hög, medan Indexsökningskostnaden är ungefär samma precis som andra kostnader.
Tabellscans
Tabellscans är testade med hjälp av smala N (320 poster per sida) och mediumbreda M (99 poster per sida) tabeller utan Index. Normalt sett så skulle Query Optimizer vid något tillfälle ändra exekveringsplanen till en parallell SQL-sats på ett multiprocessorsystem. Det här är dock specifikt avstängt så att alla tabellscans kan utföras under kontrollerbara former. Not. Parallella exekveringar
I databasserverns egenskaper i SQL Server Enterprise Manager (under Processortabben) så finns det en inställning för en ”minimum query plan threshold for considering queries for parallel execution (cost estimate)”, med standardvärdet 5. Det här värdet är exekveringsplanens uppskattade kostnad för en SQL-sats. Baserat på tabellscannens kostnadsformel i ”Kvantitetsprestandaanalys #3” så uppnådde den här kostnaden 5 841 sidor för en tabell med 99 poster per sida.
Figur 11 visar den uppmätta prestandan i tabellscans i sekunden för M tabellerna på 2x733/256K Servern. Default refererar till en SELECT utan några SQL-satshints.
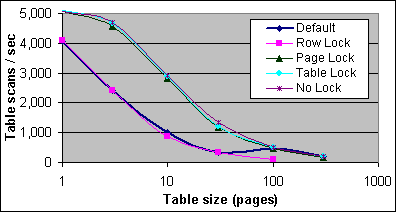
Figur 11: Prestanda för en tabellscan (2x733/256K)
Figur 12 visar den normaliserade kostnaden per tabellscan SQL-sats, efter att ha subtraherat bort basbelastningskostnaden. Plankostnaden visas också för jämförelser. Både de uppmätta kostnaderna och plankostnaderna är normaliserade till Indesökningskostnaden i fråga. De uppmätta kostnaderna är normaliserade till 32 000 CPU-cykler, och plankostnaden är normaliserad till 0,0064081. Det är valet är dock lite ologisk eftersom exekveringsplanens kostnad inte är beroende av Indexdjupet såsom den uppmätta kostnaden är. Den absoluta skalan av de uppskattade och uppmätta kostnaderna är inte lika betydelsefulla som de relativa förändringar som sker över olika tabellstorlekar. (Det hade kanske dessutom varit lämpligare att använda 30K som den uppmätta Index Seek kostnaden).
Det finns ett lite udda beteende i standardfallet (default), där tabellscankvoten faktiskt verkar öka i takt med att tabellstorleken ökar från 30 sidor till 100 sidor. Kostnaden för tabellscannen minskar från 4,27M CPU-cykler vid 30 sidor till 2,7M vid 100 sidor, och den förändringen sker faktiskt mellan tabellstorlekarna 80 sidor och 90 sidor (punkterna är inte utritade). Det är ännu inte klart än om denna förändring utlöses av antalet poster, antalet sidor eller kanske både och.
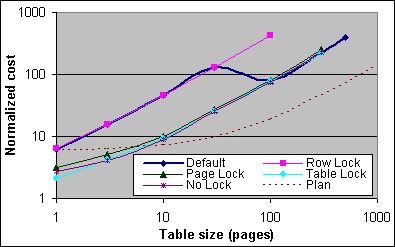
Figur 12: Normaliserade kostnader för tabellscans, uppmätta och plan (2x733/256K)
En anledning till det här kan vara det att prestandan beror på antalet poster per sida. I standardfallet så är kostnaden för den enkelsidiga M tabellscannen cirka 200K CPU-cykler jämfört med cirka 480K CPU-cykler för N1H tabellen, båda kostnaderna efter att ha subtraherat bort basbelastningen. Med en skillnad på 221 poster (320-99) så blir kostnadsskillnaden cirka 1 200 CPU-cykler per post. Det här kan leda en till att misstänka att en låsningsmekanism är involverad, och de relevanta låsningsalternativen för den här SQL-satsen är ROWLOCK, PAGLOCK, TABLOCK och NOLOCK. Ett exempel på en SQL-sats med en specifik låsning visas här nedan.
SELECT Value FROM MH WITH (PAGLOCK) WHERE ID = @ID
Det är tydligt från Figur 12 att tabellscannen i standardfallet använder sig utav en ROWLOCK för tabellstorlekar under överslagspunkten vid området av 80-90 sidor. Efter överslagspunkten så kan den uppmätta kostnaden peka på antingen sidlåsning, tabellåsning eller ingen låsning alls. SQL Server skulle inte välja att inte låsa alls, eftersom det skulle leda till att de vanliga posterna får läsas. På grund av detta så skulle de lämpliga valen vara sid- eller tabellåsning. Det här är inte ett fall där låsningen börjar med en postlåsning för att sedan stegra till en sid- eller tabellåsning, för i så fall skulle den ökande kostnaden för extra sidor över överslagspunkten minska. För att den absoluta kostnaden av tabellscannen ska kunna öka då tabellstorleken minskar, så måste förändringen av låsningsval inträffa innan scannen startar.
En viktig fråga är varför en postlåsning används, eftersom tabellscannen måste gå igenom varje post i tabellen. Varför inte helt enkelt placera en tabellåsning, eller sidlåsning, eftersom det nästan inte finns någon uppmätt skillnad alls emellan dem två. Det är möjligt att en tabell- eller sidlåsning kan störa vissa UPDATE eller DELETE operationer, men tabellåsningens och icke-låsningens lösningar är cirka 1 500 CPU-cykler billigare per sida än tabellåsningen. Notera att sidan fortfarande måste placeras i minnet med en låsning på sig, oavsett låsningstyp för att visa på att sidan är läst, och kan inte tas bort från minnet.
Figur 13 visar 2x733/256K tabellscannens normaliserade kostnad per sida, efter att man har dragit bort basbelastningen. Den uppmätta kostnaden för extra sidor i en tabellscan ligger på cirka 75-83 % av Indexsökningen. Det uppmätta värden är mycket högre än den 13 % exekveringsplankostnaden, vilket är ungefär 4 200 CPU-cykler (baserat på att 100 % = 32 000 CPU-cykler).
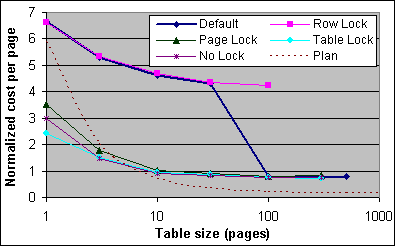
Figur 13: Kostnad per sida för olika låsningsalternativ (2x733/256K)
Serversystemet har en 64-bit (8 bytes) bred databuss, så det krävs 1 000 busscykler för att läsa en 8kb sida från minnet. Front-sidebussen kör vid 133MHz, och 733MHz CPU-kärnan kör i 5,5 gånger busshastigheten. Så för just det här systemet passerar 5 500 CPU-cykler förbi för att en 8kb sida ska kunna läsas från minnet, utan att några andra operationer övervägs. Den stora Cacheprocessorn sänker inte kostnaden av en tabellscanoperation, vilket man kanske väntade sig för en en-pass minnesoperation.
Tabelscannens kostnadsformler vid 99 poster per sida är sammanställd här nedan. Basbelastningskostnaden uppstår en gång per procedur. Kostnaden av tabellscannen (efter att man dragit bort basbelastningskostnaden) är summan av den fixerade kostnaden plus kostnaden per sida, multiplicerat med antalet sidor. Den fixerade kostnaden är inte exakt samma som den uppstartningskostnad vi definierade tidigare. Kostnaden per sida är densamma för både 2x733/256K och 4x700/2M systemen. Man anar att tabellscankostnaden utan postlåsningar är oberoende av antalet poster per sida, men detta har ännu inte testats. Kostnaden med postlåsningar är 1 200 CPU-cykler per post, plus sidkostnaden på cirka 24-26K.
Tabelscannens kostnadsformler vid 99 poster per sida
Total kostnad = basbelastning + fixerad kostnad + kostnader per sida
Pentium III (både 256K och 2M): Fixerad kostnad 60,000 CPU-cykler
Kostnad per sida:
NOLOCK: 24,000 CPU-cykler per sida
TABLOCK: 24,000 CPU-cykler per sida
PAGLOCK: 26,000 CPU-cykler per sida
ROWLOCK: 140,000 CPU-cykler per sida vid 99 poster per sida
Xeon 2.0GHz/512K: Fixerad kostnad 145,000 CPU-cykler
Kostnad per sida:
PAGLOCK: 26,000 CPU-cykler per sida
ROWLOCK: 250,000 CPU- cykler per sida vid 99 poster per sida
Figur 14 och 15 här nedan visar antalet scannade sidor per sekund på 2xPIII-733 och 4xPIII Xeon-700 systemen. Den högsta sidkvoten som är uppmätt för tabellscantesterna på dual processorsystemen är cirka 58 000 sidor i sekunden, eller 464MB/sek, vilket är mindre än hälften av 133MHz systembussen kapacitet. På 4x700MHz systemen, med en 100MHz systembuss, så är toppsidkvoten 990 000 sidor i sekunden, vilket är den fulla kapaciteten av bussens kapacitet. Den högsta tabellscankvoten på Dual Xeon 2.0GHz systemet var 158 000 sidor i sekunden, vilket du kan se i Figur 16.
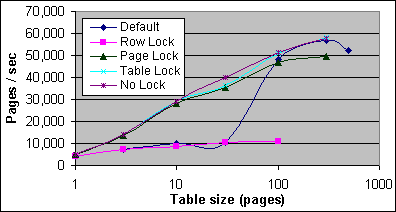
Figur 14: Tabellscan – sidor per sekund (2xPIII -733/256K)
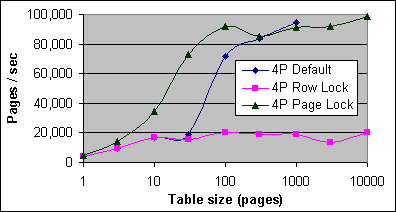
Figur 15: Tabellscan – sidor per sekund (4xPIII -700/2M)
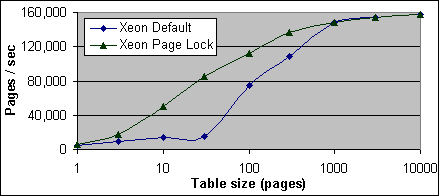
Figur 16: Tabellscan – sidor per sekund (2xXeon 2.0GHz/512K)
Slutligen så gjordes det en jämförelse i tabellscantesterna mellan flera parallella tabellscans mot en enda tabell, kontra flertalet scans mot separata tabeller. Det fanns ingen uppmätbar skillnad i prestanda. SQL Server 2000 Entersprise Edition introducerade gemensamma tabellscans för stora tabeller. Den största tabellen som har testats på det här sättet var på 506 sidor (50 000 poster) eller cirka 4MB, vilket kanske inte väger upp till SQL Serverns krav för en gemensam tabellscan.
Multi-post SELECT kostnader
SELECT-satser som innefattar flera poster är testade med användning av mediumbreda M tabeller med 50 000 poster (506 sidor), där både det Clustrade och icke-Clustrade Indexdjupet är 2. GroupID och CodeID kolumnerna är fyllda med en jämn distribution av värden så att de två SQL-satserna nedan kommer att involvera exakt lika många poster vid ett giltigt sökargument. SELECT avg(randDecimal) FROM M2x WHERE GroupID = @Group
SELECT avg(randDecimal) FROM M2x WHERE CodeID = @Code
Testsatserna ovan returnerar förminskningen av antalet multipla poster, för att på så sätt fokusera det här testet på databasserverns prestanda i stället för nätverksbandbredden. Det är två extrema fall av distribution som testas; poster med vanliga GroupID värden finns i kronologiska poster medan poster med vanliga CodeID värden är distribuerade – alltså separerade så långt som möjligt. En blandad distribution har ännu inte testats. M2C_xx tabellerna har ett Clustrat Index, vilket framtvingar distributionen. Man skapade Clustrade Index för M2N_xx tabellerna då tabellen fylldes med data, men Indexen släpptes tidigare för Bookmark på grupp-testet.
De tre exekveringsplaner som har granskats är 1) Clustrade/täckande Indexsökningar, 2) Index Seek med Bookmark Lookup, och 3) tabellscan. Det täckande Indexet innefattar både SARG och den önskade kolumnen. Index Seek med Bookmark Lookup planen är testade på ID kolumnen i en tabell med ett Clustrat Index (M2C_xx), samt på en grupporganiserad tabell (M2N_xx). I båda fallen så används det icke-Clustrade Indexet endast på den enda kolumnen som är specificerat i sökvillkoret. SQL-satsen tas om hand genom en Indexlösning för att tvinga fram en specifik exekveringsplan. Tabellscannen är testad på grupporganiserade tabeller (M2H_xx).
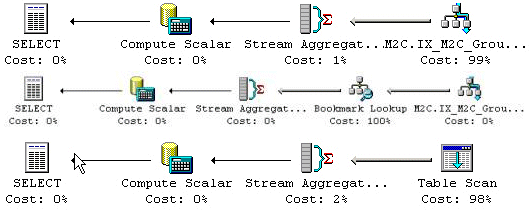
Figur 17: Exekveringsplaner för multi-post SQL-satser med förminskningsfunktion
Multi-post Clustrade/täckta Indexkostnader
Figur 18 och 19 visar den täckta multi-post Indexsökningens SQL-satskostnader. Figur 18:s kostnader är normaliserade till 32 000 CPU-cykler för de uppmätta kostnaderna på 2x733MHz och 0,0064081 för plankostnaden mindre än – eller lika med – 1GB. Figur 19:s kostnader är normaliserade till 24 000 CPU-cykler för de uppmätta kostnaderna på 4x700, och 0,003283025 för plankostnaderna över 1GB. Det täckande Indexet får plats med 500 poster per Indexsida, vilket påverkar plankostnaden (0,000740741 per sida och 0,0000011 per post). Figur 20 visar den normaliserade uppmätta kostnaden på 4x700 och med en plankostnad per post på över 1GB.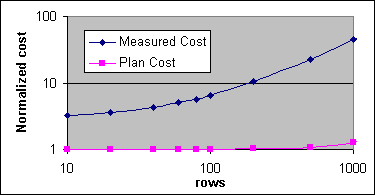
Figur 18: SQL-satskostnader för multi-post förminskningsfunktioner, täckande Indexsökning (2x733/256K)
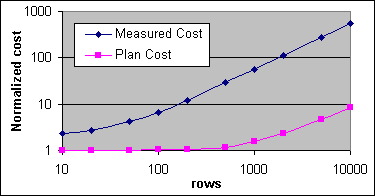
Figur 19: SQL-satskostnader för multi-post förminskningsfunktioner, täckande Indexsökning (4x700/2M)
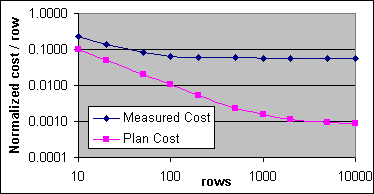
Figur 20: Kostnad per post för Clustrad Indexsökning (4x700/2M)
Det finns en viktig skillnad mellan de uppmätta kostnaderna och plankostnaderna. Plankostnaden är väldigt rät upp till 500 poster, och det beror på att den fixerade uppstartningskostnaden är mycket högre än de variabla kostnaderna, samt den höga postdensiteten i det täckande Indexet. Men plankostnaderna skulle ändå ha varit mycket lägre än de uppmätta kostnaderna om postdensiteten hade varit lägre. PAGLOCK lösningen påverkar inte de uppmätta kostnaderna av en täckande Indexsökningsplan. Den uppmätta kostnadsformeln för den täckande SQL-satsen beskrivs här nedan. Den fixerade kostnaden på 2xPIII verkar vara 90K CPU-cykler, vilket är mer än de 20K för den extra basbelastningskostnaden som vi observerade förut vid enkel-post Indexsökningen, plus Indexsökningskostnaden på 32K. Den fixerade kostnaden på 4xPIII Xeon är 90K CPU-cykler, vilket också är mer än Indexsökningskostnaden på 24K plus minimal extra belastning.
Kostnadsformler för multi-post Clustrade och täckande Index
Total kostnad = basbelastning + fixerad kostnad + kostnader per post
Fixerad kostnad:
PIII 2x733/256K: 90,000 CPU-cykler
PIII Xeon 4x700/2M: 40,000 CPU-cykler
Xeon 2x2.0GHz/512K: 140,000 CPU-cykler
Kostnad per post:
Pentium III 1,300 CPU-cykler per post (båda)
Xeon 1,800 CPU-cykler per post
Multi-post Bookmark Lookup och tabellscanskostnader
Figur 21 visar den uppmätta prestandan jämfört med antalet poster, vilka har förminskats för SELECT-satsen genom att ange GroupID som SARG, där de valda posterna är i kronologisk ordning. 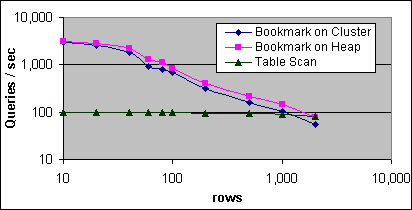
Figur 21: Prestanda för Bookmark och tabellscan (2x733/256K)
Vid ett lågt antal poster (30 poster eller färre) så är prestandan delvis driven av basbelastningskostnaden. Avtaget vid 60 poster beror på förändringen av antalet generatorladdningsklienterna. Över 80 poster så avgörs prestandan till stor del av antalet poster där basbelastningskostnade är låg i relation till den allmänna procedurskostnaden.
Figur 22 visar de uppmätta kostnaderna och exekveringsplankostnaderna för Indexsökningen med Bookmark Lookup, tabellscan och täckande (listat som Clustrade) Indexplaner på 2x733/256K systemet. Plankostnaderna är normaliserade för mer (eller lika med) 1GB.
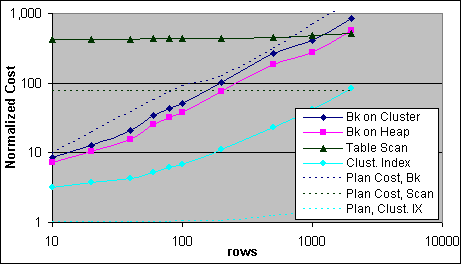
Figur 22: Uppmätta kostnader och plankostnader för Bookmark och tabellscan (2x733/256K)
Figur 23 här nedan visar den normaliserade kostnaden per post för resultaten från Figur 22. Den uppmätta kostnaden per post drar bara bort basbelastningskostnaden, innan den divideras med antalet poster. Plankostnaden för Clustrad- eller täckande Indexsökning är för låg för att kunna visas i den här skalan.
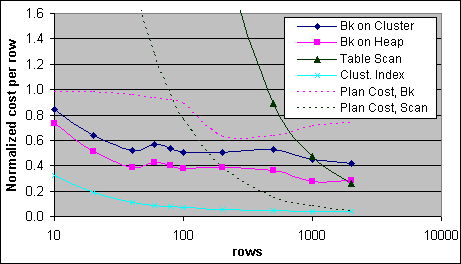
Figur 23: Normaliserad kostnad per post (2xPIII –733/256K)
Bookmark Lookupen på tabellen med ett Clustrat Index kräver en 2 I/O:s Indexsökning, jämfört med en enda I/O för Bookmark Lookupen på en grupp. Exekveringsplankostnaden av Bookmark-planen visar ett ”knä” vid 100-200 poster, vilket beror på att Bookmark Lookup komponentens I/O-kostnad har en mycket lägre multiple än uppskattningen på antalet poster. Den förutsedda överslagspunkten mellan Bookmarkplanen till tabellscanplanen inträffar vid 85 poster, precis där som Indexsökningen med Bookmark Lookup planen kräver 87 I/O operationer för en grupp och 172 I/O operationer för en tabell med ett Clustrat Index.
Plankostnaden för en Indexsökning med Bookmark Lookup exekveringsplan ligger i närheten av en per Bookmark Lookup vid ett lågt antal poster, och sjunker till cirka 63 % av en Indexsökning per post vid 200-500 poster, innan det åter höjs till 73 % vid 2000 poster. Den uppmätta Bookmark Lookup kostnaden per post sjunker å andra sidan väldigt fort till 40 % av Indexsökningen för en grupp, och 50 % för tabellen med ett Clustrat Index vid 40 poster eller fler. En vidare sänkning för Bookmark Lookup kostnader till 30 % och 40 % inträffar i den ordningen vid 1000 poster och högre. Överslagskostnaden mellan Indexsökningen med Bookmark Lookup och tabellscannens exekveringsplaner inträffar inte förrän precis över 1000 poster för en tabell med ett Clustrat Index, och precis under 2000 poster för en grupp. Plankostnaden underskattar tabellscankostnaden med cirka 5X och överskattar Bookmark Lookup kostnaden med cirka 2-3X.
En mindre viktig punkt från ovanstående test är tabellscankostnaden jämfört med antalet påverkade poster. Exekveringsplankostnaden av en tabellscan utan förminskingsfunktioner beror endast på det totala antalet poster och sidor i tabellen, och inte på antalet returnerade poster. Plankostnaden med förminskningsfunktion lägger till en förminskning-per-post-kostnad på 0,0000001 per post, vilket vanligtvis är ett ganska irrelevant bidrag till den totala plankostnaden. Den uppmätta kostnaden visar att varje förminskad post lägger till cirka 1 300 CPU-cykler till tabellscankostnaden, eller 4 % av en Indexsökning, vilket fortfarande är lågt (men märkbart) i relation till den totala kostnaden.
Kostnadsformlerna för en multi-post Bookmak Lookup kan beskrivas ungefär som följer. Basbelastningskostnaden tillkommer, som alltid. Det finns en fixerad kostnad som skulle kunna inkluderas i den extra belastningen som beskrevs tidigare, som också inkluderar uppstartningskostnaden som tillhör SQL-satsen – såsom den initierande Indexsökningen.
Kostnadsformler för en multi-post Bookmak Lookup
Total kostnad = basbelastning + fixerad kostnad + kostnader per post
Fixerad kostnad:
PIII 2x733/256K: 110,000 CPU-cykler
PIII Xeon 4x700/2M: 24,000 CPU-cykler
Xeon 2.0GHz/512K: 150,000 CPU-cykler (Kronologisk)
Xeon 2.0GHz/512K: 180,000 CPU-cykler (Distribuerad)
Figur 24 och 25 här nedan jämför Bookmark Lookup kostnaden per post under olika villkor på 2x733/256K och 4x700/2M systemen. Variationerna inkluderar tabellstruktur (Clustrat Index eller grupp), postdistribution (kronologisk eller distribuerad) samt låsningar (ingen eller PAGLOCK). Kostnaden per post drar först bort basbelastningskostnaden (140K eller 210K) samt den fixerade kostnaden (110K för PIII-733/256K, 24K för PIII Xeon 700/2M). (Notera att kostnaden per post i Figur 23 endast drar bort basbelastningskostnaden). Den oväntade toppen vid 5000 poster för 4x700/2M systemets Clustrade Index kronologiska Bookmark-kostnad (blå linje med hela rutern) kan möjligtvis vara ett mätningsfel. Man kan se från resultaten att Bookmark Lookup kostnaden ökar med 5-20 % då posterna är icke-kronologiska relativt till de kronologiska posterna.
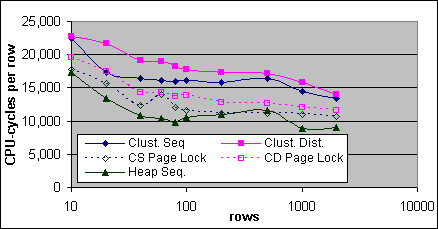
Figur 24: Bookmark Lookup kostnader per post (2xPIII –733/256K)
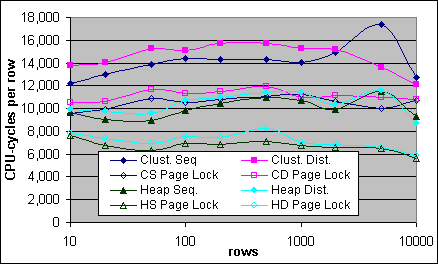
Figur 25: Bookmark Lookup kostnader per post (2xPIII Xeon –700/2M)
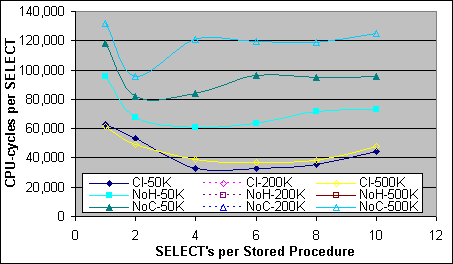
Figur 26 visar Bookmark Lookup kostnaden per post för 2xXeon 2.0GHz/512K systemet. Bookmark Lookup kostnaden per post finns listad i Tabell 4. Alla dessa mätningar gjordes på tabeller med 50 000 poster, där både det Clustrade och icke-Clustrade Indexdjupet är 2. För större tabeller så bidrar Indexsökningsdelen av Index Seek med Bookmark Lookup-planen till den fixerade kostnaden, inte till kostnaden per återhämtad post. Bookmark Lookup kostnaden per post på en grupp bör inte påverkas, eftersom det inte finns något beroende av Indexdjup. Bookmark Lookup kostnaden på en tabell med ett Clustrat Index däremot beror på Indexdjupet eller på antalet poster, så man förväntar sig att den kommer att vara dyrare.

Figur 26: Bookmark Lookup kostnad per post (2xXeon –2.0/512K)
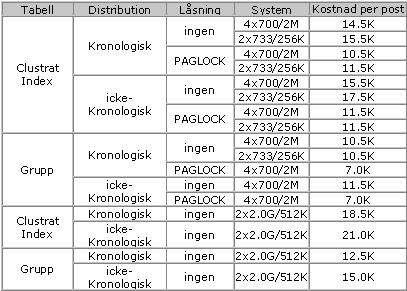
Tabell 4: Bookmark Lookup kostnad per post för en tabell med 50 000 poster
Tabellscannen och de Clustrade/täckande Indexsökningarnas kostnadsformler för Pentium III visas här nedan för jämförelse. De fixerade kostnaderna här kan skilja sig lite från Bookmark Lookupens fixerade kostnader.
Multi-post tabellscan och täckande Index kostnadsformler
Täckande Index : fixerad kostnad + (1 300 × poster)
Tabellscan : fixerad kostnad + (26 000 × sidor) + (1 300 × poster)
Huvudobservationen för multi-post SELECT-satser är att det kan finnas en väldig skillnad mellan den punkt där din Query Optimizer övergår från exekveringsplanen till en tabellscan, och den faktiska överslagspunkten.
Andra viktiga punkter inkluderar följande. Bookmark Lookups är mindre dyra för grupporganiserade tabeller än för tabeller med ett Clustrat Index. Det är ofta rekommenderat att tabeller bör ha ett Clustrat Index. Om Clustring endast ger fördel till en liten fraktion av SQL-satserna (delvis av antalet involverade poster) så kan det vara bättre att låta tabellen vara en grupp. PAGLOCK lösningen kan reducera kostnaden av Bookmark Lookupen markant. När det inte går att undvika att Bookmark Lookupen involverar många poster så bör du överväga att låta bli postlåsningar, ifall typen av data anses vara relativt statisk.
Loop JOINs
Loop JOINen uppvisar tre olika beteenden i exekveringsplanens kostnadsformler, där Clustrade och täckande Index var tillgängliga för att inte behöva några Bookmark Lookups. Både Fall 1 och Fall 2 specificerar ett sökargument på endast den yttre källan. I Fall 1 så är den inre källan en liten tabell med en enda sida, och i Fall 2 så är inte den inre källan så liten. Fall 3 har ett sökargument specificerat på båda tabellerna, och det täckande Indexet på båda tabellerna börjar med sökargumentet. Figur 27 och 28 visar den normaliserade uppmätta kostnaden och plankostnaden för var och en av de tre Loop JOIN-fallen på 2x600/256K (samma skalfaktor, 32 000 CPU-cykler, som 2x733/256K) och på 4x700/2M Servrarna (endast för Fall 2 och 3). Man har subtraherat bort basbelastningskostnaden på 140K CPU-cykler. Plankostnaderna är normaliserade till mindre än (eller lika med) 1GB för 2x600 systemet, och mer än 1GB för 4x700 systemet.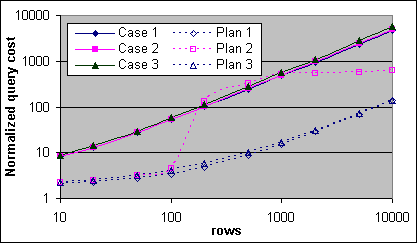
Figur 27: Normaliserad Loop JOIN kostnad, uppmätt och plan (2x600/256K)
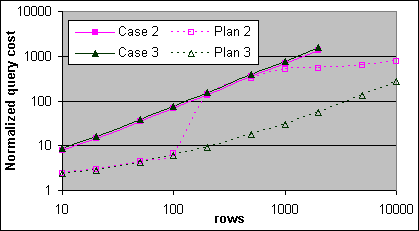
Figur 28: Normaliserad Loop JOIN kostnad, uppmätt och plan (4x700/2M)
Figur 29 visar den normaliserade kostnaden per post för 2x600/256K systemet. De uppmätta kostnaderna har dragit bort basbelastningen (140K CPU-cykler), den extra belastningen (20K) samt 32K för den första posten från den yttre källans Indexsökning, normaliserade till 32K CPU-cykler. Plankostnaden subtraherar den yttre källans enkelpost Indexsökning (0,0064081) och är normaliserad till samma Indexsökningskostnad. Notera att detta inte är kostnadsskillnader, såsom i kapitlet om exekveringsplankostnader.
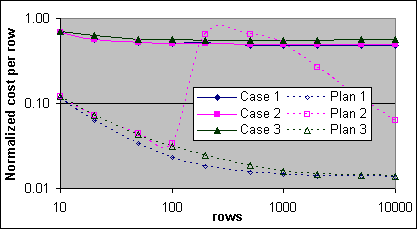
Figur 29: Loop JOIN kostnad per post, uppmätt och plan (2x600/256K)
Figur 30 och 31 visar kostnaden per post i CPU-cykler för 2x600/256K och 4x700/2M systemen. Kostnaden per post är härledd på samma sätt som i Figur 29, förutom det att kostnaderna inte är normaliserade, och det att 4P systemet inte har någon extra belastningskostnad.
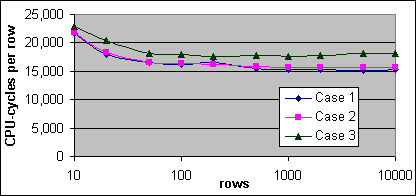
Figur 30: Loop JOIN kostnad per post (2x600/256K)
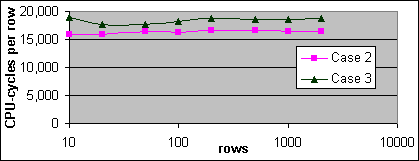
Figur 31: Loop JOIN kostnad per post (4x700/2M)
Plankostnaden per post för Loop JOINen i Fall 2 är lite högre än för Loop JOINen i Fall 1 vid ett lågt antal poster, och visar ett kraftigt hopp uppåt mellan 100 och 200 poster. Plankostnaden per extra post för Loop JOINen i Fall 3 liknar den i Fall 2 vid ett lågt antal poster, men sjunker gradvis ned mot Loop JOINens kostnadsstruktur i Fall 1.
De uppmätta Loop JOIN kostnaderna för Fall 1 och 2 är närapå identiska. Men det bör inte komma som någon överraskning, eftersom den uppmätta kostnaden för den Clustrade Indexsökningen på enkelsidetabellen nästan är densamma som för en tabell med 50 000 poster. En Loop JOIN utför vanligtvis upprepade Indexsökningar mot den inre källtabellen. Dessutom är Loop JOIN kostnaden väldigt lik kostnaden för en Bookmark Lookup på ett Clustrat Index. Fast Loop JOIN kostnaden varierar inte mellan kronologisk och icke-kronologisk distribution av de inre källposterna.
Den uppmätta Loop JOIN kostnaden i Fall 3 är lite högre än för de i Fall 1 och 2. Den uppmätta kostnaden för varje extra post är lite mindre än för den enskilde Indexsökningskostnaden för en enda post, men mycket högre än plankostnaderna. Det är väntat att den uppmätta kostnaden per extra post bör vara högre för större tabeller där Indexdjupet är större än 2, likt den Indexsökningskostnad som beskrevs tidigare.
Loop, Hash och Merge JOINs
Figur 32 och 33 de uppmätta kostnaderna och plankostnaderna för Loop, Hash och Merge JOINs på 2x600/256K och 4x700/2M systemen. För de uppmätta kostnaderna så har basbelastningskostnaderna dragits bort. Den uppmätta Loop JOIN kostnaden är kostnaden för Fall 2, vilket är lite lägre än för den i Fall 3. Plankostnaden för Loop JOIN är från Fall 3, vilket inte har det ovanliga beteenden som kan observeras över 100 poster. 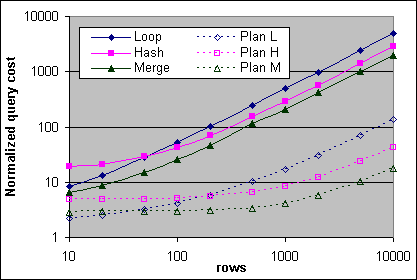
Figur 32: Kostnad för Loop, Hash och Merge JOIN (2x600/256K)
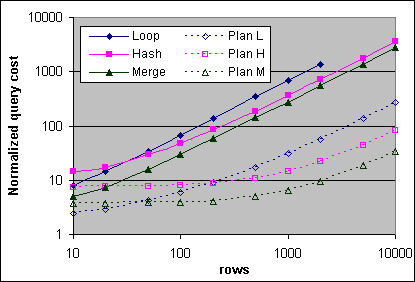
Figur 33: Kostnad för Loop, Hash och Merge JOIN (4x700/2M)
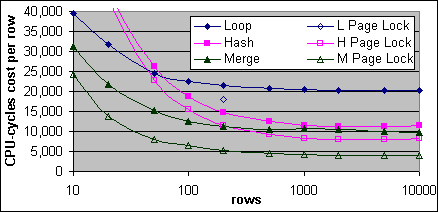
De uppmätta Loop, Hash och Merge JOIN kostnaderna är på ett sätt någorlunda lika plankostnaderna. Merge JOINen är alltid mindre dyr än Hash JOINen, då de allmänna (en-till-många) Merge JOIN villkoren uppfylls. Loop JOINen är relativt effektiv vid ett lågt antal poster. Det är förväntat att en Loop JOIN som involverar få poster från den yttre källan och många poster från den inre källan ska vara relativt effektiv, men detta har inte granskat på djupet ännu. Loop JOINen är effektivare än Hash JOINen vid ett lågt antal poster. Vid ett högre antal poster så är Hash JOINen mindre dyr än Loop JOINen för de JOINs som involverar lika många poster från båda källorna, men överslagspunkten inträffar vid ett lägre antal poster än förväntat enligt plankostnaderna (cirka 50 kontra cirka 160). Det är inte så tydligt att Loop JOINen är effektivare än Merge JOINen vid ett lågt antal poster. Den uppmätta Merge JOIN kostnaden är billigare än Loop JOINen redan vid 10 poster, faktum är att detta troligen är sant redan vid 5 poster.
Figur 34 visar den normaliserade kostnaden per post för de uppmätta kostnaderna på 2x600/256K systemet och för plankostnader mindre än (eller lika med) 1GB. Precis som i Figur 29 så har man från de uppmätta kostnaderna dragit bort basbelastningskostnaden, den extra belastningen samt den första posten från den yttre källans Indexsökning, normaliserad till 32K CPU-cykler. För plankostnaden har man dragit bort den yttre källans enkel-post-Indexsökning och är normaliserad till kostnaden för enkel-post-Indexsökningen.
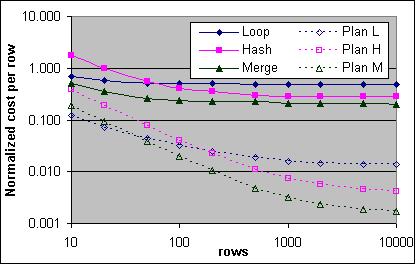
Figur 34: Kostnad per post för Loop, Hash och Merge JOIN (2x600/256K)
Den uppmätta kostnaden per extra post är mycket högre än plankostnaderna för alla tre typer av JOINs. Dessutom så har inte de uppmätta kostnaderna så hög separation mellan JOIN typerna, vilket förutsågs av plankostnaderna. Plankostnaderna reflekterar användandet av kompakta täckande Index med över 500 poster per sida. Ett mindre packat Clustrat Index skulle ha bidragit mer från den extra I/O kostnaden per sida på 0,00074074, vilket resulterar i en mindre separation mellan de tre typerna av JOINs.
JOINs och låsningar
Exekveringsplanens kostnadsformler räknar inte in låsningslösningarna. Tabellscans och Bookmark Lookups drar tydligt fördel från slappa låsningskrav. Figur 35, 36 och 37 visar de uppmätta Loop, Hash och Merge JOINs kostnaderna med inga låsningar, samt med PAGLOCK hints på båda tabellerna. 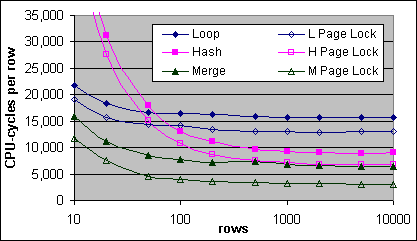
Figur 35: JOIN kostnader per post, med och utan låsningshints (2x600/256K)
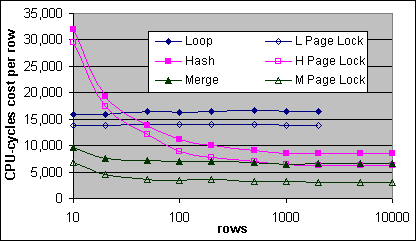
Figur 36: JOIN kostnader per post, med och utan låsningshints (4x700/2M)
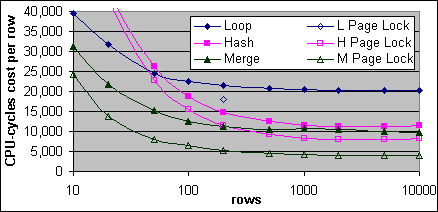
Figur 37: JOIN kostnader per post, med och utan låsningshints (2xXeon)
PAGLOCK hint reducerar kostnaderna för alla tre typer av JOINs med cirka 3 000 CPU-cykler per post. Merge JOINen testades också med en PAGLOCK hint på endast den yttre källan, sen än en gång fast på endast den inre källan. PAGLOCK hint gav en fördel på cirka 1 500 CPU-cykler per post i båda fallen.
Merge JOIN med sortering, och många-till-många Merge JOINs
Figur 38 jämför de vanliga Merge JOIN och Hash JOIN med en många-till-många Merge JOIN samt en Merge JOIN med sortering på 4x700/2M systemet.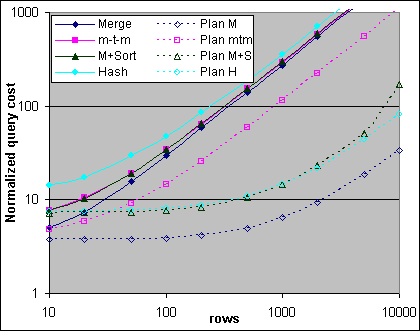
Figur 38: Kostnader för många-till-många samt Merge med sortering (4x700/2M)
Figur 39 visar de normaliserade kostnaderna per post på 4x700/2M systemet. För de uppmätta kostnaderna så har man dragit bort basbelastningen samt den yttre källans Indexsökningskostnader för den första posten. För plankostnaderna så har man bara dragit bort den yttre källans Indexsökningskostnader för den första posten.
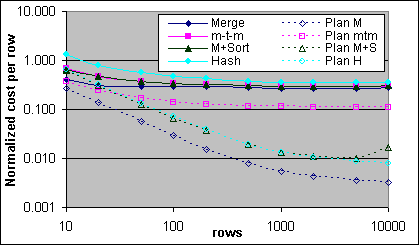
Figur 39: Kostnader för många-till-många samt Merge med sortering (4x700/2M)
Figur 40 visar den uppmätta kostnaden per post i CPU-cykler per post. Plankostnaden för många-till-många Merge JOINen blir snabbt mycket dyrare än någon av de andra JOIN typerna vid mer än 50 poster.
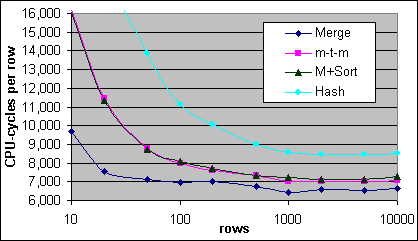
Figur 40: Kostnader för många-till-många samt Merge med sortering (4x700/2M)
Merge JOIN med sortering börjar med en lite lägre kostnad än Hash JOINen, och blir sen lite dyrare innan den stiger kraftigt i kostnad någonstans runt 5 000 poster. Sorteringskostnadens beteende över 5 000 poster har ännu inte granskats noggrant. De uppmätta kostnaderna visar inte på dessa överslagspunkter. Både många-till-många Merge JOINen och Merge JOIN med sortering är dyrare än en vanlig Merge JOIN, men båda är billigare än en Hash JOIN – åtminstone upp till 5 000 poster. Varken många-till-många Merge JOINen eller Merge JOIN med sortering har blivit grundligt undersökta, så en varning kan vara på sin plats här.
Merge och Hash JOINs, en-till-många
Figur 41 jämför den uppmätta kostnaden för Merge och Hash JOINs med sidlåsning på båda tabellerna, där varje post från den yttre källan matchar exakt en eller två poster från den inre källan, vilket är noterat av 1:n relationen.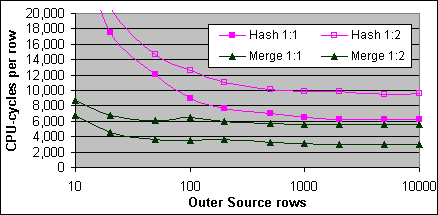
Figur 41: Hash och Merge JOIN, 1:1 och 1:2 (4x700/2M)
Loop JOINen (som inte visas) verkar lägga till cirka 2 000 CPU-cykler för varje extra post i den inre källan, Merge JOINen lägger till 2 500 och Hash JOINen lägger till cirka 3 500 CPU-cykler.
Summering av JOIN kostnader
Tabell 5 summerar de observerade JOIN kostnadsformlerna.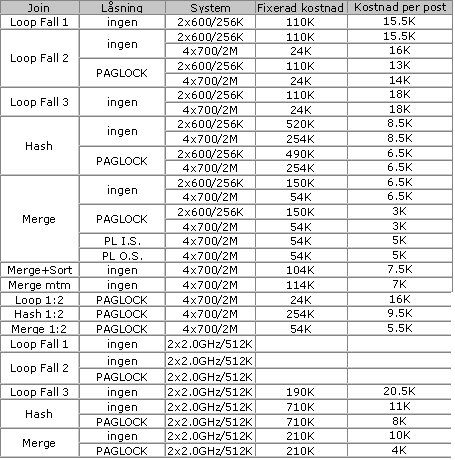
Tabell 5: JOIN kostnadsformler
Som tidigare så består den totala lagrade procedurkostnaden av basbelastningskostnaden, en fixerad kostnad samt en kostnad per post.
JOIN kostnadsformel
Total kostnad = basbelastning + fixerad kostnad + kostnader per post
Den fixerade kostnaden innefattar alla extra belastningskostnader (dominant i de små Cachesystemen) samt uppstartningskostnader som tillhör själva SQL-satsen. Om det skulle finnas fler än en SQL-sats per lagrad procedur så tillkommer basbelastningskostnaden endast en gång, men det är fortfarande oklart hur man hanterar den fixerade kostnaden. Det är troligtvis så att den extra belastningen på små Cachesystem (i området av 20-30K CPU-cykler) ingår en gång, och att påminnelsen om den fixerade kostnaden tillhör SQL-satsen. På stora Cachesystem så tillhör den fixerade kostnaden högst troligt enbart SQL-satsen.
Summering
Som summering så kan man nämna att de viktigaste punkterna då man jämför en SQL-sats uppmätta kostnader med plankostnader, är 1) plankostnaderna underskattar kostnaden av extra poster i alla operationer, förutom i Bookmark Lookupen vilken är överskattad, och 2) plankostnaden har inte med låsningstyp i sina beräkningar. Kopplat till det faktum att tabellscankostnader är underskattade så använder exekveringsplanen en tabellscan i stället för en Indexsökning med Bookmark Lookup, vid ett mycket lägre antal poster än vad det egentligen borde. Underskattning av kostnaden för extra poster i JOINs leder till att det används en Loop JOIN, trots att Merge eller Hash JOIN skulle varit mer effektiv.När det gäller låsningstyper så har varje databasapplikation en blandning av operationstabeller och ”relativt statiska” tabeller. Du bör allvarligt överväga att stänga av postlåsningar för statiska data – prestandavinsten kan bli enorm. Små tabellscans kan dessutom bli oproportionellt dyra om du låser standarder till postlåsningar.
Bookmark Lookup kostnaden beror på den underliggande tabellen. En tabell bör inte Clustras utan någon tanke på den ökande kostnaden för Bookmark Lookups på en Clustrad tabell. Hur du ska välja till fördel av Clustringen tas upp i en senare artikel.
0 Kommentarer